第九章:设计一个网页爬虫 (Design A Web Crawler)
在本章中,我们将重点讨论网页爬虫的设计,这是一个有趣且经典的系统设计面试问题。
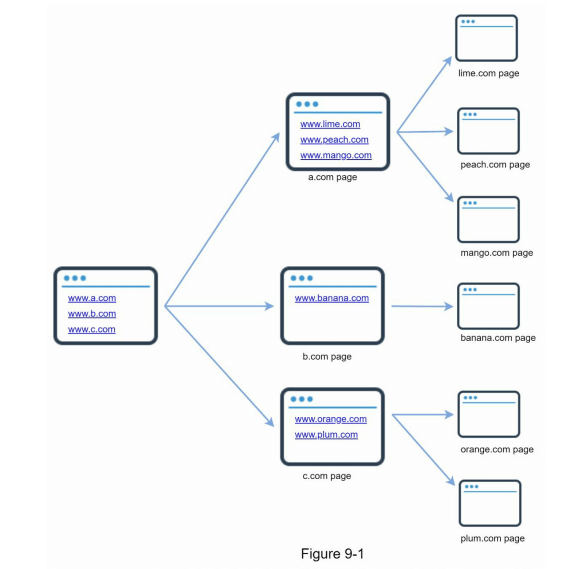
网页爬虫,也被称为机器人或蜘蛛,广泛应用于搜索引擎,以发现网络上的新内容或更新的内容。内容可以是网页、图片、视频、PDF文件等。一个爬虫最初会收集一些网页,然后通过跟踪这些网页上的链接,收集新的内容。图9-1展示了爬虫过程的可视化示例。
爬虫有许多用途:
- 搜索引擎索引:这是最常见的使用场景。爬虫会收集网页,为搜索引擎创建本地索引。例如,Googlebot 是 Google 搜索引擎背后的网页爬虫。
- 网络存档:这是为了将网络信息收集并保存以供将来使用的过程。例如,许多国家图书馆都会运行爬虫来存档网站。著名的例子有美国国会图书馆 [1] 和欧盟网络档案 [2]。
- 网络挖掘:互联网的爆炸性增长为数据挖掘带来了前所未有的机会。网络挖掘帮助从互联网上发现有用的知识。例如,顶尖的金融公司会使用爬虫下载股东会议记录和年度报告,以了解关键的公司举措。
- 网络监控:爬虫帮助监控互联网上的版权和商标侵权。例如,Digimarc[3] 利用爬虫发现盗版作品并进行报告。
开发一个网页爬虫的复杂性取决于我们想要支持的规模。它可以是一个小型的学校项目,只需几个小时即可完成;也可以是一个庞大的项目,需要专门的工程团队不断改进。因此,我们将探讨爬虫支持的规模和功能。
第 1 步 - 理解问题并确定设计范围
网页爬虫的基本算法非常简单:
- 给定一组URL,下载这些URL指向的所有网页。
- 从这些网页中提取URL。
- 将新的URL添加到待下载的URL列表中。重复这三个步骤。
那么,网页爬虫的工作是否真的如上述算法那么简单呢?并不完全是。设计一个大规模可扩展的网页爬虫是一个极其复杂的任务。在面试时间内很难设计出一个庞大的网页爬虫系统。因此,在开始设计之前,我们必须通过提问来了解需求,并确定设计的范围:
- 候选人:爬虫的主要用途是什么?是用于搜索引擎索引、数据挖掘,还是其他用途?
- 面试官:用于搜索引擎索引。
- 候选人:每个月爬虫需要收集多少网页?
- 面试官:10亿个网页。
- 候选人:包括哪些内容类型?仅限HTML,还是包括PDF、图片等其他内容类型?
- 面试官:仅限HTML。
- 候选人:我们是否需要考虑新添加或编辑过的网页?
- 面试官:是的,我们需要考虑新添加或编辑过的网页。
- 候选人:我们是否需要存储爬取的HTML页面?
- 面试官:是的,最多存储5年。
- 候选人:如何处理重复内容的网页?
- 面试官:对于重复内容的页面应忽略。
以上是一些你可以向面试官提问的示例问题。理解需求并澄清不确定性是至关重要的。即使你被要求设计一个看似简单的产品,如网页爬虫,你和面试官对产品的假设可能并不相同。
除了功能需求之外,还应注意以下网页爬虫的关键特性:
- 可扩展性:互联网规模巨大,网页数量以十亿计。网页爬虫应通过并行化来实现极高的效率。
- 健壮性:互联网充满了陷阱,如不良的HTML代码、无响应的服务器、系统崩溃、恶意链接等。爬虫必须能够处理这些极端情况。
- 礼貌性:爬虫不应在短时间内对同一个网站发出过多的请求。
- 可扩展性:系统应具有灵活性,以便在支持新的内容类型时只需进行最小的更改。例如,如果未来需要爬取图片文件,我们不应该需要重新设计整个系统。
粗略估算
以下估算基于许多假设,因此与面试官沟通以确保一致理解是非常重要的。
- 假设每个月下载10亿个网页。
- 每秒请求数 (QPS):1,000,000,000 页 / 30天 / 24小时 / 3600秒 ≈ 400 页/秒。
- 峰值 QPS = 2 * QPS = 800 页/秒。
- 假设每个网页的平均大小为 500KB。
- 存储需求:10亿页 x 500KB = 500TB 存储需求每月。如果你对数字存储单位不太清楚,可以参考第2章的“2的幂”部分。
- 假设数据存储5年,那么 500TB * 12个月 * 5年 = 30PB。需要30PB的存储空间来保存5年的内容。
第 2 步 - 提出高层设计并获得认同
在明确需求之后,我们可以开始构建高层设计。借鉴以往关于网页爬虫的研究 [4] [5],我们提出了一个高层设计,如图9-2所示。首先,我们将逐一探讨各个设计组件的功能,然后再逐步分析爬虫的工作流程。
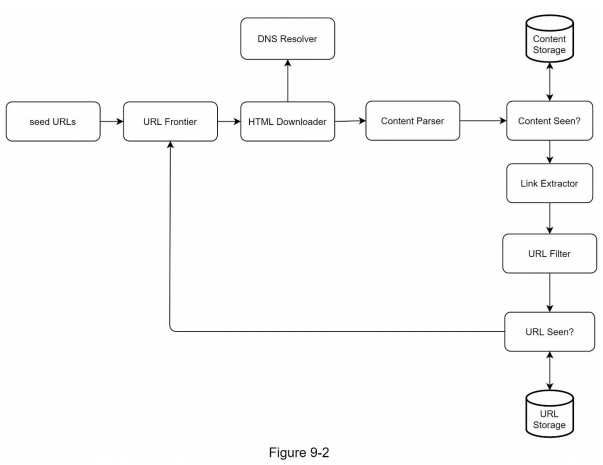
种子URL (Seed URLs)
网页爬虫使用种子URL作为爬取过程的起点。例如,要爬取一所大学网站的所有网页,一个直观的方法是选择该大学的域名作为种子URL。
如果要爬取整个互联网,就需要更加有创造性地选择种子URL。一个好的种子URL可以作为一个有效的起点,帮助爬虫遍历尽可能多的链接。通常的策略是将整个URL空间划分为较小的部分。第一种建议的方法是基于地域划分,因为不同国家有不同的热门网站。另一种方式是根据主题来选择种子URL,例如,可以将URL空间划分为购物、体育、医疗保健等领域。
种子URL的选择是一个开放性的问题,你不需要给出完美答案,只需要清晰地表达你的思路即可。
URL 前沿队列 (URL Frontier)
大多数现代网页爬虫将爬取状态分为两部分:待下载的URL和已下载的URL。存储待下载URL的组件称为URL前沿队列。你可以将它理解为一个先进先出(FIFO)的队列。有关URL前沿的详细信息可以参考后续深入探讨部分。
HTML 下载器 (HTML Downloader)
HTML下载器负责从互联网下载网页,这些URL由URL前沿队列提供。
DNS 解析器 (DNS Resolver)
要下载网页,必须将URL转换为IP地址。HTML下载器调用DNS解析器以获取URL对应的IP地址。例如,URL www.wikipedia.org 将会被转换为IP地址198.35.26.96(截至2019年3月5日)。
内容解析器 (Content Parser)
下载网页后,必须对其进行解析和验证,因为格式不正确的网页可能引发问题并浪费存储空间。在爬虫服务器上实现内容解析器会减慢爬取过程,因此内容解析器是一个独立的组件。
内容检测 (Content Seen?)
在线研究 [6] 表明,大约29%的网页内容是重复的,这可能导致相同的内容被多次存储。我们引入了“内容检测”数据结构以消除数据冗余并缩短处理时间。它有助于检测系统中之前存储的内容。要比较两个HTML文档,我们可以逐字逐句进行比较,但这种方法速度慢,特别是在处理数十亿网页时。一个更高效的方法是比较两个网页的哈希值 [7]。
内容存储 (Content Storage)
内容存储系统用于存储HTML内容。选择存储系统时,需要考虑数据类型、数据大小、访问频率、数据存续期等因素。存储方式包括磁盘和内存:
- 大部分内容存储在磁盘上,因为数据集过大,无法全部存储在内存中。
- 热门内容则存储在内存中,以减少访问延迟。
URL 提取器 (URL Extractor)
URL提取器从HTML页面中解析并提取链接。图9-3展示了链接提取过程的一个示例。相对路径通过添加 “https://en.wikipedia.org” 前缀转换为绝对URL。

URL 过滤器 (URL Filter)
URL过滤器用于排除某些内容类型、文件扩展名、错误链接以及在“黑名单”中的站点的URL。
URL 已访问检测 (URL Seen?)
“URL已访问” 是一个数据结构,用于跟踪之前已访问的URL或已经在前沿队列中的URL。“URL已访问”有助于避免多次添加相同的URL,因为这会增加服务器负载并可能导致无限循环。
布隆过滤器和哈希表是实现“URL已访问”组件的常用技术。此处不详细介绍布隆过滤器和哈希表的具体实现,详情可参考参考文献 [4] [8]。
URL 存储 (URL Storage)
URL存储用于保存已经访问过的URL。
到目前为止,我们已经讨论了系统的每个组件。接下来,我们将它们组合在一起,解释整个爬虫的工作流程。
网页爬虫工作流程 (Web Crawler Workflow)
为了更好地逐步解释工作流程,设计图中添加了顺序编号,如图9-4所示。
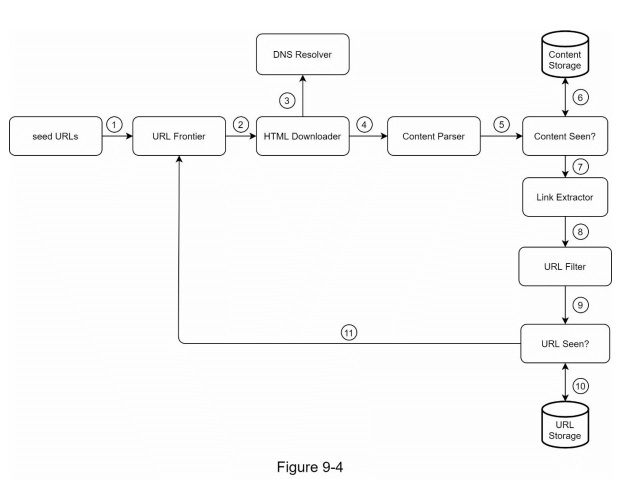
第 1 步:将种子 URL 添加到 URL 前沿
第 2 步:HTML 下载器从 URL 前沿获取 URL 列表。
第 3 步:HTML 下载器从 DNS 解析器获取 URL 的 IP 地址并开始下载。
第 4 步:内容解析器解析 HTML 页面并检查页面是否格式错误。
第 5 步:在内容解析和验证后,将其传递给“内容是否已见?”组件。
第 6 步:“内容是否已见?”组件检查 HTML 页面是否已存在于存储中。
- 如果已存在于存储中,意味着在不同的 URL 中已经处理过相同的内容。在这种情况下,该 HTML 页面将被丢弃。
- 如果不在存储中,系统之前未处理过相同的内容。内容将被传递给链接提取器。
第 7 步:链接提取器从 HTML 页面中提取链接。
第 8 步:提取的链接将传递给 URL 过滤器。
第 9 步:经过过滤的链接将传递给“URL 是否已见?”组件。
第 10 步:“URL 是否已见?”组件检查 URL 是否已存在于存储中。如果是,说明之前已处理过,无需进行任何操作。
第 11 步:如果 URL 之前未被处理,将其添加到 URL 前沿。
第 3 步 - 设计深入探讨
到目前为止,我们已经讨论了高层设计。接下来,我们将深入讨论一些最重要的构建组件和技术:
- 深度优先搜索(DFS)与广度优先搜索(BFS)
- URL 前沿
- HTML 下载器
- 健壮性
- 可扩展性
- 检测和避免问题内容
DFS 与 BFS
你可以将网络视为一个有向图,其中网页作为节点,超链接(URLs)作为边。爬虫过程可以看作是从一个网页遍历到其他网页。两种常见的图遍历算法是 DFS 和 BFS。然而,DFS 通常不是一个好的选择,因为其深度可能非常大。
BFS 通常被网络爬虫使用,并通过先进先出(FIFO)队列实现。在 FIFO 队列中,URLs 按照入队的顺序出队。然而,这种实现存在两个问题:
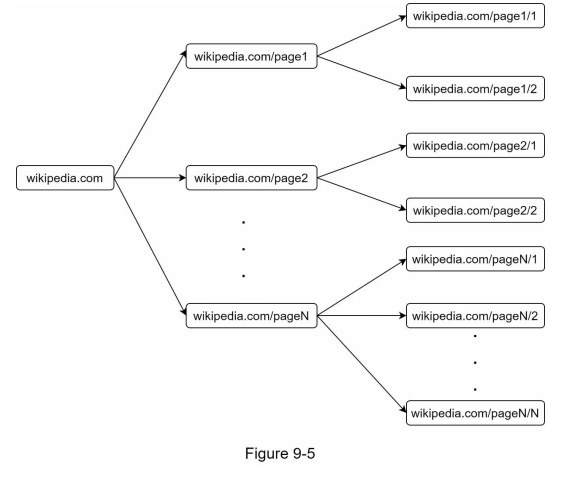
- 来自同一网页的大多数链接都指向同一主机。在图 9-5 中,所有的链接都指向内部链接(wikipedia.com),这使得爬虫在处理来自同一主机(wikipedia.com)的 URLs 时非常忙碌。当爬虫尝试并行下载网页时,维基百科的服务器将会被请求淹没。这被认为是不礼貌的。
- 标准 BFS 并未考虑 URL 的优先级。网络是庞大的,并非每个页面的质量和重要性都相同。因此,我们可能希望根据页面排名、网络流量、更新频率等因素来优先处理 URLs。
URL 前沿队列 (URL Frontier)
URL 前沿有助于解决这些问题。URL 前沿是一种数据结构,用于存储待下载的 URLs。URL 前沿是确保礼貌性、URL 优先级和新鲜度的重要组成部分。关于 URL 前沿的一些值得注意的论文在参考材料中提到 [5] [9]。这些论文的主要发现如下:
礼貌性 (Politeness)
一般来说,网络爬虫应该避免在短时间内向同一主机发送过多请求。发送过多请求被认为是不“礼貌”的,甚至可能被视为拒绝服务(DOS)攻击。例如,如果没有任何限制,爬虫可以每秒向同一网站发送数千个请求,这可能会淹没网络服务器。
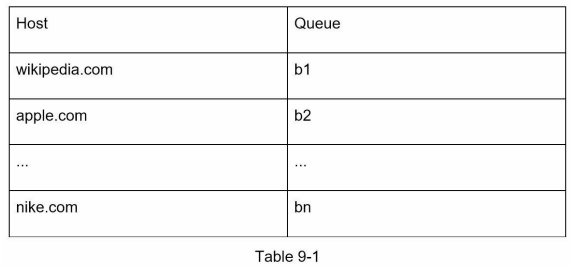
强制礼貌性的总体思路是从同一主机一次下载一个页面。在两个下载任务之间可以添加延迟。礼貌性约束是通过维护从网站主机名到下载(工作)线程的映射来实现的。每个下载线程都有一个独立的 FIFO 队列,并仅下载从该队列中获得的 URLs。图 9-6 显示了管理礼貌性的设计。
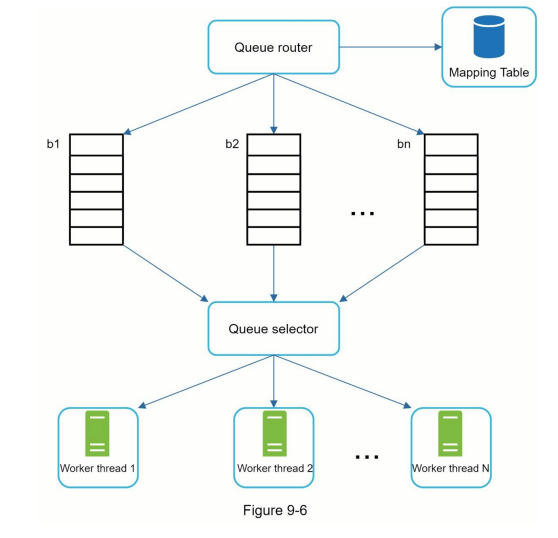
- 队列路由器:确保每个队列(b1, b2, … bn)只包含来自同一主机的 URLs。
- 映射表:将每个主机映射到一个队列。
- FIFO 队列 b1, b2 到 bn:每个队列包含来自同一主机的 URLs。
- 队列选择器:每个工作线程映射到一个 FIFO 队列,并仅从该队列下载 URLs。队列选择逻辑由队列选择器完成。
- 工作线程 1 到 N:工作线程从同一主机逐个下载网页。在两个下载任务之间可以添加延迟。
优先级 (Priority)
来自讨论论坛的随机帖子与苹果主页上的帖子权重截然不同。尽管它们都包含“Apple”这个关键词,但爬虫先抓取苹果主页是合乎逻辑的。
我们根据有用性对 URLs 进行优先级排序,这可以通过 PageRank [10]、网站流量、更新频率等进行衡量。“优先级管理器”是处理 URL 优先级的组件。有关此概念的详细信息,请参考参考材料[5] [10]。
图 9-7 显示了管理 URL 优先级的设计。
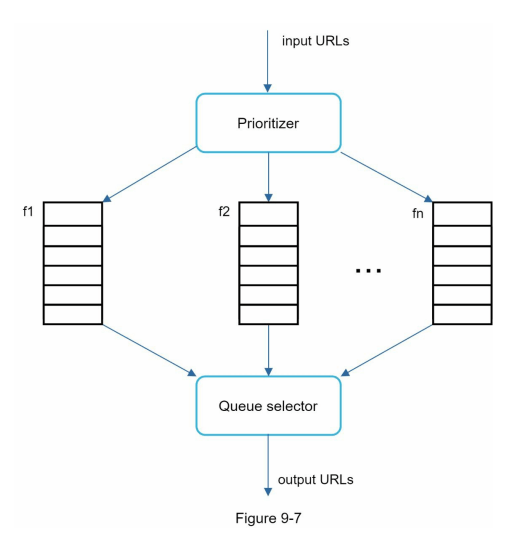
- 优先级管理器:接收 URLs 作为输入并计算优先级。
- 队列 f1 到 fn:每个队列都有分配的优先级。优先级高的队列被选择的概率更高。
- 队列选择器:随机选择一个队列,但更倾向于优先级高的队列。
图 9-8 展示了 URL 前沿设计,包含两个模块:
- 前队列:管理优先级
- 后队列:管理礼貌性
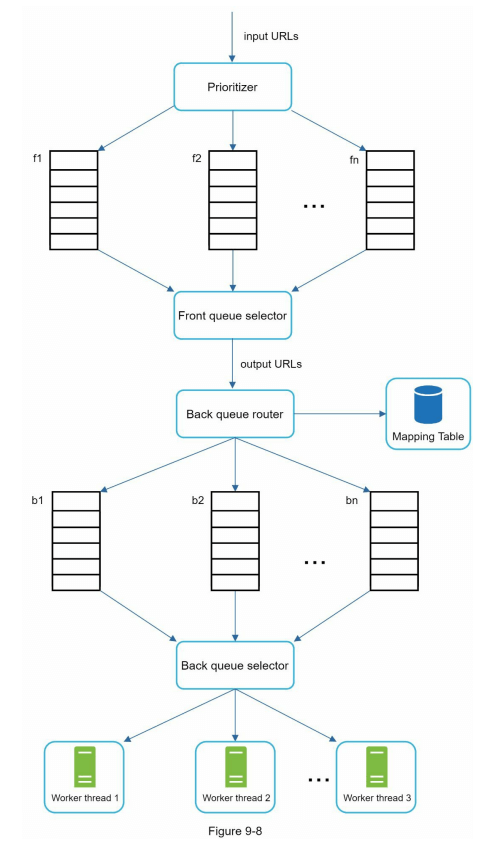
新鲜度 (Freshness)
网页不断被添加、删除和编辑。网络爬虫必须定期重新抓取已下载的页面,以保持数据集的新鲜。重新抓取所有 URLs 是耗时且资源密集型的。优化新鲜度的一些策略如下:
- 根据网页的更新历史进行重新抓取。
- 优先处理 URLs,首先更频繁地重新抓取重要页面。
URL 前沿的存储 (Storage for URL Frontier)
在现实世界的搜索引擎爬取中,前沿中的 URL 数量可能达到数亿 [4]。将所有内容都放在内存中既不耐用也不可扩展。将所有内容存储在磁盘上也不理想,因为磁盘速度较慢,容易成为爬取的瓶颈。
我们采用了一种混合方法。大多数 URLs 存储在磁盘上,因此存储空间不是问题。为了减少从磁盘读取和写入的成本,我们在内存中维护缓冲区以进行入队/出队操作。缓冲区中的数据会定期写入磁盘。
HTML 下载器 (HTML Downloader)
HTML 下载器使用 HTTP 协议从互联网下载网页。在讨论 HTML 下载器之前,我们先来看一下爬虫协议。
Robots.txt
Robots.txt,即爬虫排除协议,是网站用来与爬虫进行通信的标准。它指定了爬虫允许下载的页面。在尝试抓取一个网站之前,爬虫应该首先检查其对应的 robots.txt,并遵循其规则。为避免重复下载 robots.txt 文件,我们缓存该文件的结果。该文件会定期下载并保存到缓存中。以下是来自 https://www.amazon.com/robots.txt 的一段 robots.txt 文件。一些目录,如 creatorhub,禁止 Google 爬虫访问。
User-agent: Googlebot
Disallow: /creatorhub/*
Disallow: /rss/people/*/reviews
Disallow: /gp/pdp/rss/*/reviews
Disallow: /gp/cdp/member-reviews/
Disallow: /gp/aw/cr/除了 robots.txt,性能优化是我们将讨论的 HTML 下载器的另一个重要概念。
性能优化
以下是 HTML 下载器的一些性能优化措施:
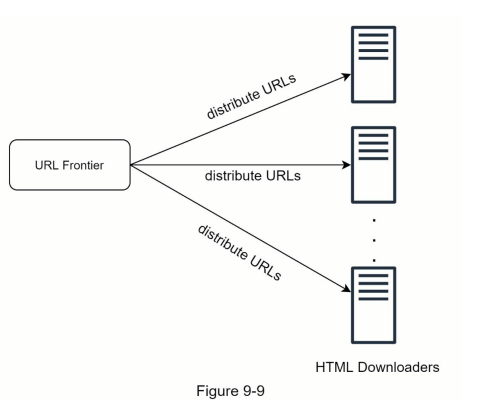
- 分布式爬取
为了实现高性能,爬取任务被分配到多个服务器,每个服务器运行多个线程。URL 空间被划分为更小的部分;因此,每个下载器负责一部分 URLs。图 9-9 显示了分布式爬取的示例。
缓存 DNS 解析器
DNS 解析器是爬虫的瓶颈,因为由于许多 DNS 接口的同步特性,DNS 请求可能需要时间。DNS 响应时间范围从 10 毫秒到 200 毫秒。一旦爬虫线程发起 DNS 请求,其他线程将被阻塞,直到第一个请求完成。维护 DNS 缓存以避免频繁调用 DNS 是一种有效的速度优化技术。我们的 DNS 缓存保持域名与 IP 地址的映射,并由 cron 作业定期更新。位置局部性
在地理上分布爬取服务器。当爬取服务器更靠近网站主机时,爬虫的下载时间会更快。位置局部性设计适用于大多数系统组件:爬取服务器、缓存、队列、存储等。短时间超时
某些 web 服务器响应缓慢或可能根本不响应。为了避免长时间等待,指定最大等待时间。如果主机在预定义时间内未响应,爬虫将停止该作业并抓取其他页面。
健壮性
除了性能优化,健壮性也是一个重要的考虑因素。我们提出了一些提高系统健壮性的方法:
- 一致性哈希:这有助于在下载器之间分配负载。可以使用一致性哈希添加或删除新的下载器服务器。有关更多详细信息,请参阅第 5 章:设计一致性哈希。
- 保存爬取状态和数据:为了防止失败,爬取状态和数据被写入存储系统。中断的爬取可以通过加载保存的状态和数据轻松重启。
- 异常处理:在大规模系统中,错误是不可避免且常见的。爬虫必须优雅地处理异常,避免系统崩溃。
- 数据验证:这是防止系统错误的重要措施。
可扩展性
由于几乎所有系统都会不断发展,设计目标之一是使系统足够灵活,以支持新内容类型。爬虫可以通过插入新模块进行扩展。图 9-10 显示了如何添加新模块。
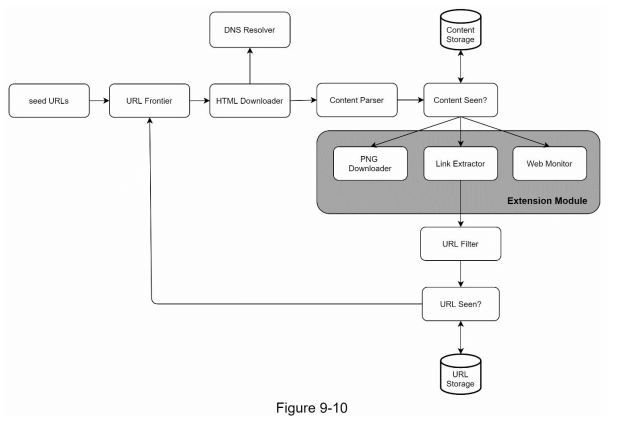
- PNG 下载器模块被插入以下载 PNG 文件。
- 网页监控模块被添加以监控网络并防止侵犯版权和商标。
检测和避免问题内容
本节讨论了冗余、无意义或有害内容的检测和预防。
冗余内容
如前所述,近 30% 的网页是重复的。哈希值或校验和有助于检测重复内容 [11]。爬虫陷阱
爬虫陷阱是指导致爬虫陷入无限循环的网页。例如,以下列出一个无限深的目录结构:
www.spidertrapexample.com/foo/bar/foo/bar/foo/bar/…可以通过设置 URL 的最大长度来避免此类爬虫陷阱。然而,没有一种通用的解决方案可以检测爬虫陷阱。由于在此类网站上发现了异常数量的网页,包含爬虫陷阱的网站容易识别。尽管很难开发自动算法来避免爬虫陷阱,但用户可以手动验证并识别爬虫陷阱,并选择从爬虫中排除这些网站或应用一些自定义的 URL 过滤器。
- 数据噪声
某些内容的价值很小或没有价值,例如广告、代码片段、垃圾 URL 等。这些内容对爬虫没有用处,应该尽可能排除。
第 4 步 - 总结
在本章中,我们首先讨论了一个优秀爬虫的特点:可扩展性、礼貌性、可扩展性和鲁棒性。接着,我们提出了设计方案并讨论了关键组件。构建一个可扩展的网络爬虫并非易事,因为网络庞大且充满陷阱。尽管我们已覆盖了许多主题,但仍然遗漏了一些相关的重要讨论点:
服务器端渲染:许多网站使用 JavaScript、AJAX 等脚本动态生成链接。如果我们直接下载和解析网页,将无法获取动态生成的链接。为了解决这个问题,我们在解析页面之前首先执行服务器端渲染(也称为动态渲染)[12]。
过滤不必要的页面:由于存储容量和爬取资源有限,反垃圾邮件组件在过滤低质量和垃圾页面方面非常有用 [13] [14]。
数据库复制与分片:复制和分片等技术用于提高数据层的可用性、可扩展性和可靠性。
横向扩展:对于大规模爬取,需要数百甚至数千台服务器来执行下载任务。关键是保持服务器无状态。
可用性、一致性和可靠性:这些概念是任何大型系统成功的核心。我们在第 1 章中详细讨论了这些概念。请回顾一下这些主题。
分析:收集和分析数据是任何系统的重要组成部分,因为数据是微调的关键成分。
恭喜你走到这里!现在给自己拍拍背,做得好!
参考文献
[1] US Library of Congress: https://www.loc.gov/websites/
[2] EU Web Archive: http://data.europa.eu/webarchive
[3] Digimarc: https://www.digimarc.com/products/digimarc-services/piracy-intelligence
[4] Heydon A., Najork M. Mercator: A scalable, extensible web crawler World Wide Web, 2 (4) (1999), pp. 219-229
[5] By Christopher Olston, Marc Najork: Web Crawling. http://infolab.stanford.edu/~olston/publications/crawling_survey.pdf
[6] 29% Of Sites Face Duplicate Content Issues: https://tinyurl.com/y6tmh55y
[7] Rabin M.O., et al. Fingerprinting by random polynomials Center for Research in Computing Techn., Aiken Computation Laboratory, Univ. (1981)
[8] B. H. Bloom, “Space/time trade-offs in hash coding with allowable errors,” Communications of the ACM, vol. 13, no. 7, pp. 422–426, 1970.
[9] Donald J. Patterson, Web Crawling: https://www.ics.uci.edu/~lopes/teaching/cs221W12/slides/Lecture05.pdf
[10] L. Page, S. Brin, R. Motwani, and T. Winograd, “The PageRank citation ranking: Bringing order to the web,” Technical Report, Stanford University, 1998.
[11] Burton Bloom. Space/time trade-offs in hash coding with allowable errors. Communications of the ACM, 13(7), pages 422--426, July 1970.
[12] Google Dynamic Rendering: https://developers.google.com/search/docs/guides/dynamic-rendering
[13] T. Urvoy, T. Lavergne, and P. Filoche, “Tracking web spam with hidden style similarity,” in Proceedings of the 2nd International Workshop on Adversarial Information Retrieval on the Web, 2006.
[14] H.-T. Lee, D. Leonard, X. Wang, and D. Loguinov, “IRLbot: Scaling to 6 billion pages and beyond,” in Proceedings of the 17th International World Wide Web Conference, 2008.