第五章:设计一致性哈希 (Design Consistent Hashing)
为了实现横向扩展,重要的是将请求/数据高效且均匀地分布到各个服务器上。一致性哈希(Consistent Hashing)是一种常用的技术,可以实现这一目标。但在此之前,让我们深入探讨一下这个问题。
重哈希问题 (The rehashing problem)
如果你有 n 台缓存服务器,常见的负载均衡方式是使用以下哈希方法:
serverIndex = hash(key) % N其中 N 是服务器池的大小。
让我们通过一个例子来说明其工作原理。如表 5-1 所示,我们有 4 台服务器和 8 个字符串键(string keys)及其对应的哈希值。
为了找到存储键的服务器,我们执行模运算 f(key) % 4。例如,hash(key0) % 4 = 1 意味着客户端必须联系服务器 1 来获取缓存数据。
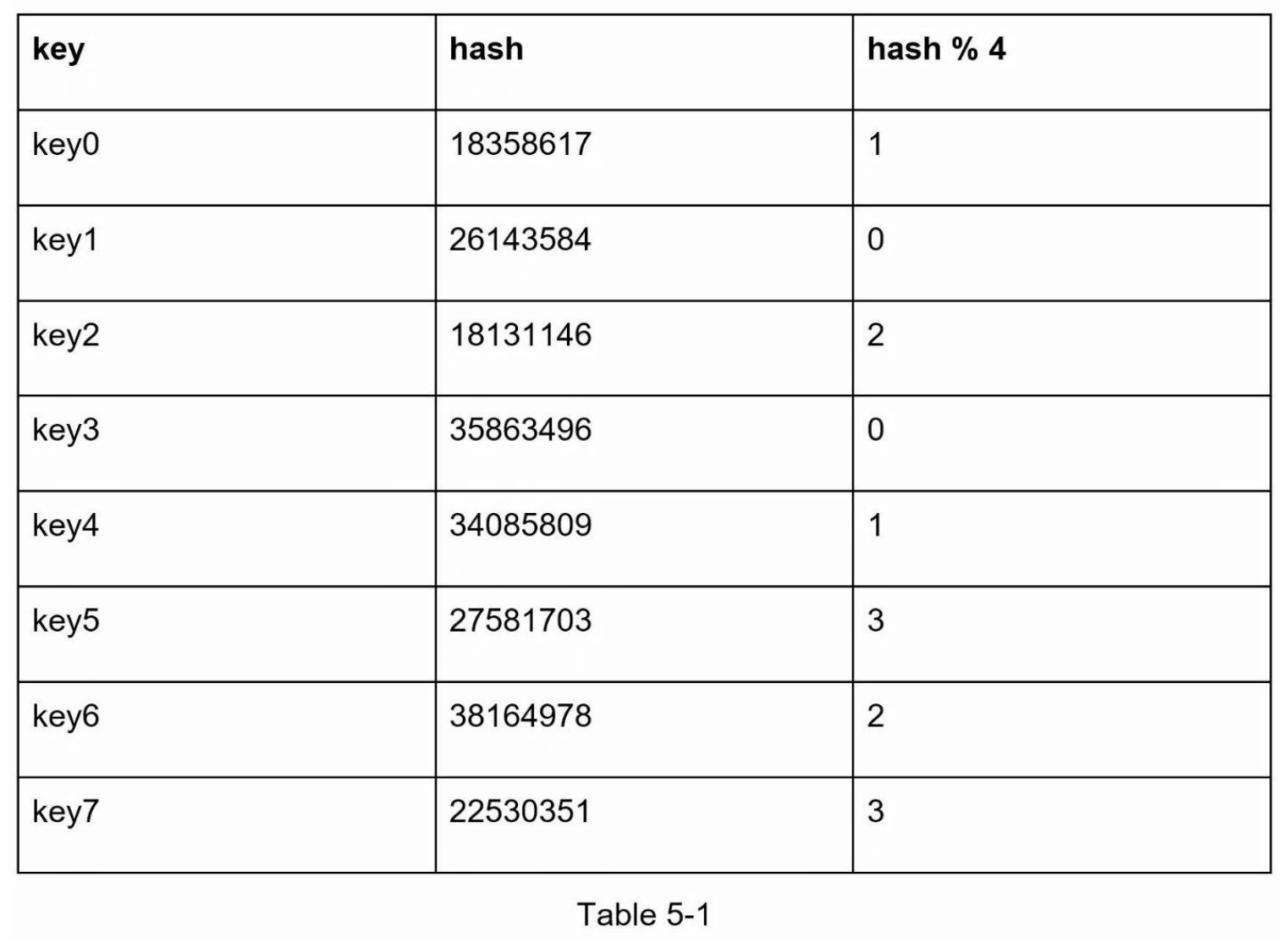
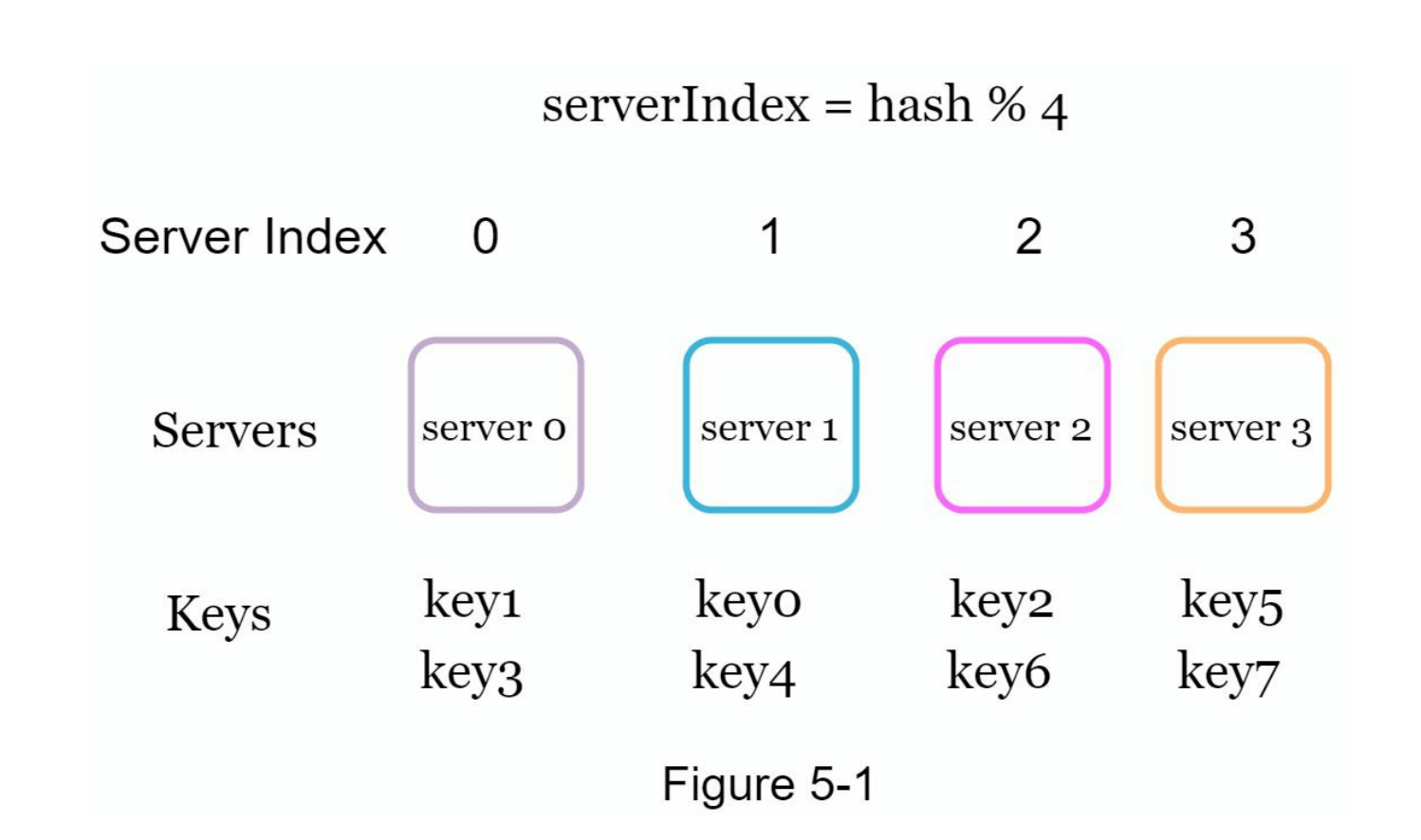
图 5-1 显示了基于表 5-1 的键分布情况。
这种方法在服务器池的大小固定且数据分布均匀时效果很好。然而,当新增服务器或移除现有服务器时,就会出现问题。例如,如果服务器1下线,服务器池的大小变为3。使用相同的哈希函数,我们会得到相同的键的哈希值。但由于服务器数量减少了1,应用模运算会得到不同的服务器索引。
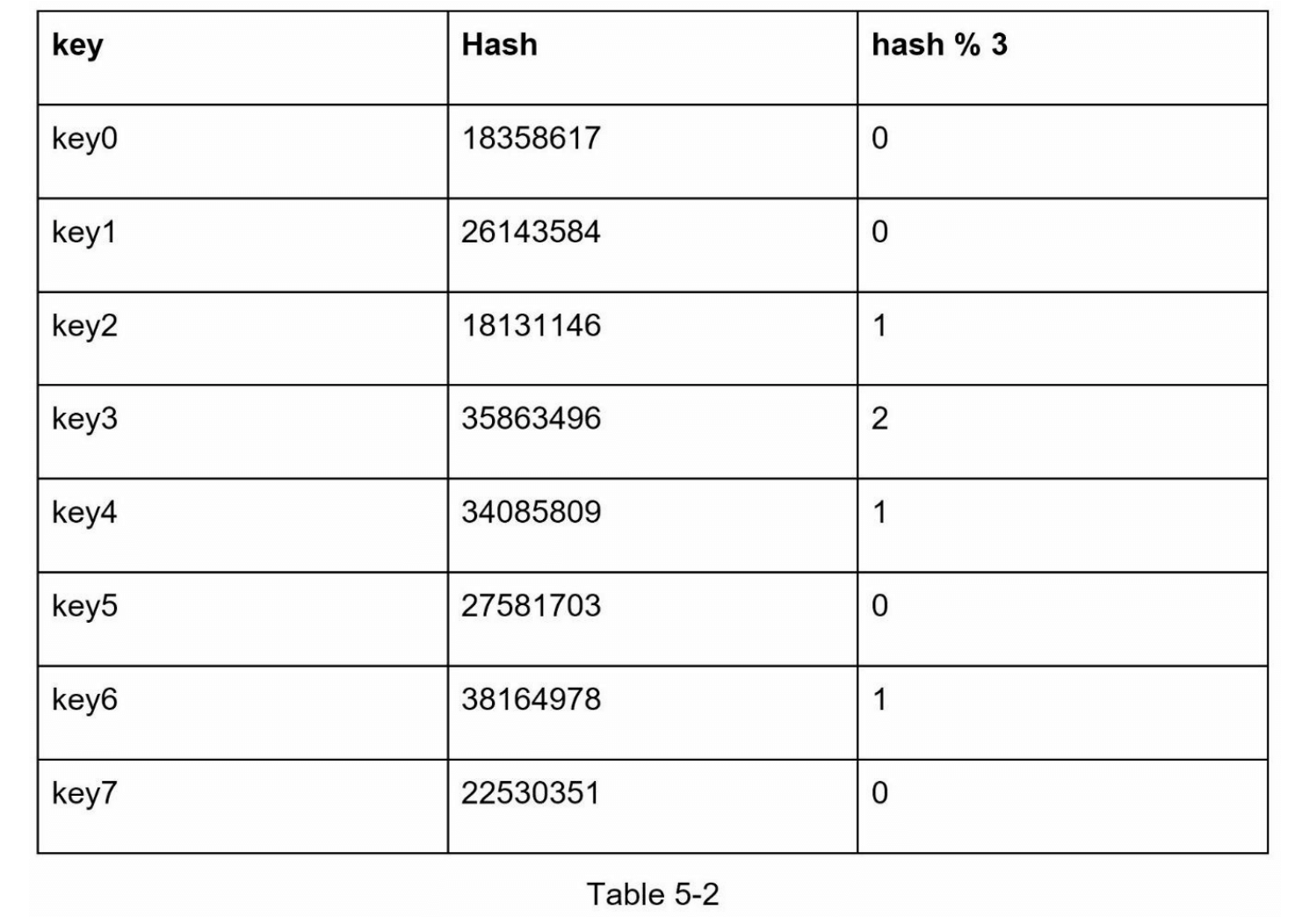
通过将哈希值对3取模 hash % 3 ,我们可以得到如表 5-2 所示的结果。图 5-2 则展示了基于表 5-2 的新键分布情况。
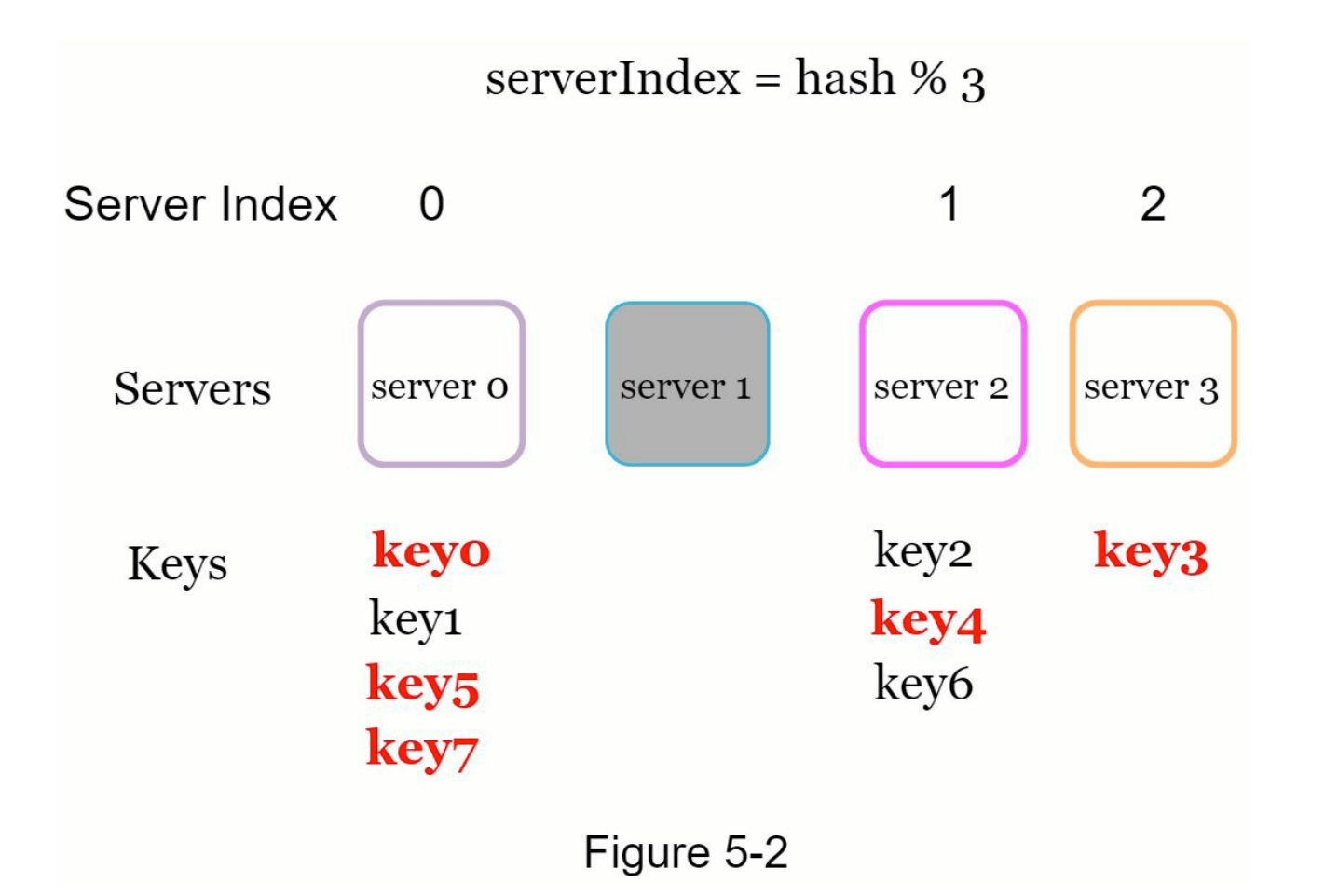
如图 5-2 所示,大多数键都被重新分配,而不仅仅是最初存储在下线服务器(服务器1)上的键。这意味着当服务器1下线时,大多数缓存客户端会连接到错误的服务器来获取数据,从而引发大量缓存未命中(cache miss)问题。一致性哈希是一种有效的技术,可以缓解这一问题。
一致性哈希 (Consistent hashing)
引用自维基百科:“一致性哈希(Consistent Hashing)是一种特殊的哈希方法,当哈希表的大小调整时,使用一致性哈希平均只需要重新映射 k/n 个键,其中 k 是键的数量,n 是槽的数量。相比之下,在大多数传统哈希表中,数组槽的数量发生变化时,几乎所有键都需要重新映射 [1]。”
哈希空间与哈希环 (Hash space and hash ring)
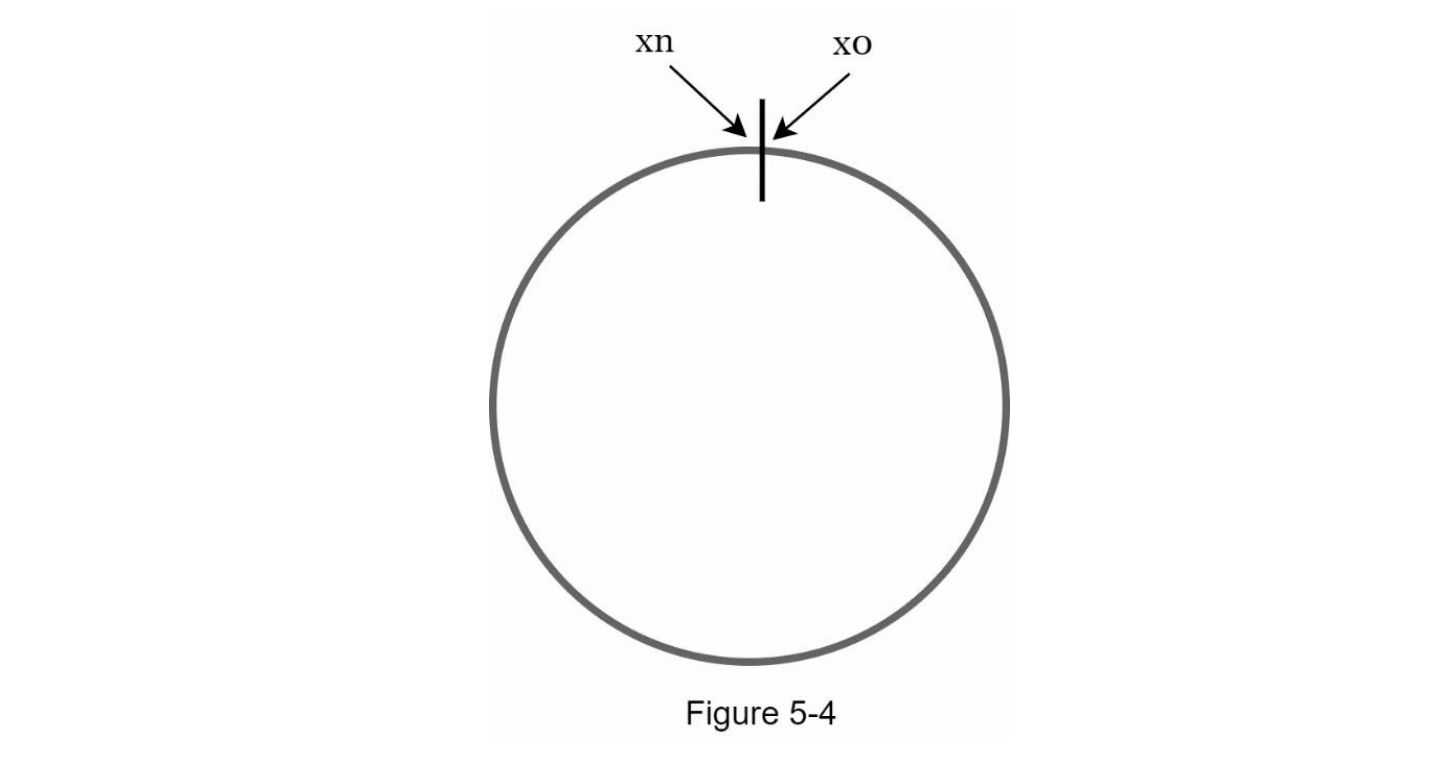
现在我们了解了一致性哈希的定义,让我们来看看它是如何工作的。假设使用 SHA-1 作为哈希函数 f,哈希函数的输出范围为:x0, x1, x2, x3, …, xn。在密码学中,SHA-1 的哈希空间从 0 到 2^160 - 1。这意味着 x0 对应于 0,xn 对应于 2^160 - 1,其他所有哈希值都介于 0 和 2^160 - 1 之间。图 5-3 显示了哈希空间。

通过连接两端,我们得到如图 5-4 所示的哈希环。
哈希服务器 (Hash servers)
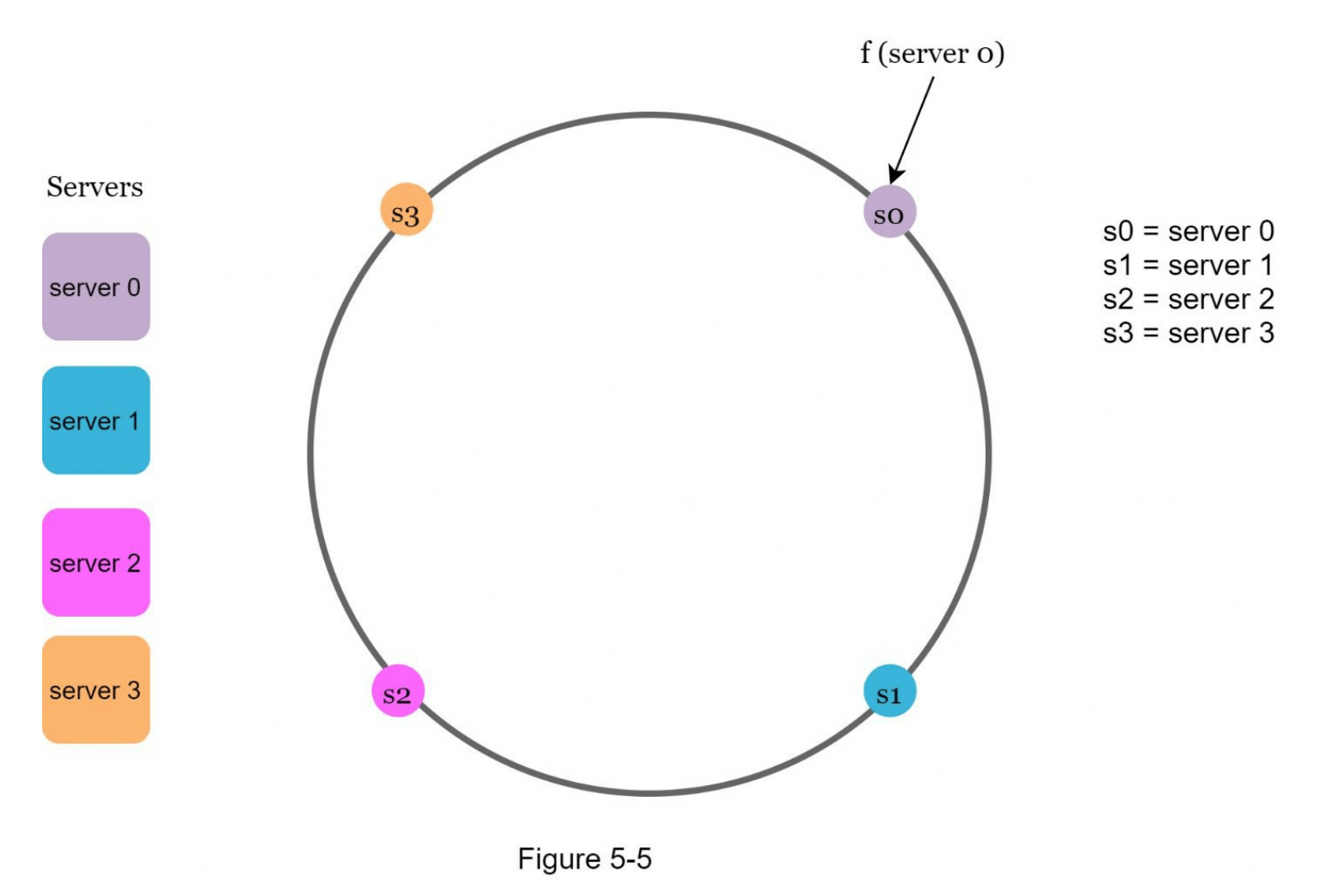
使用相同的哈希函数 f,我们可以根据服务器的IP或名称将服务器映射到哈希环上。图5-5展示了4台服务器被映射到哈希环中的情况。
哈希键 (Hash keys)
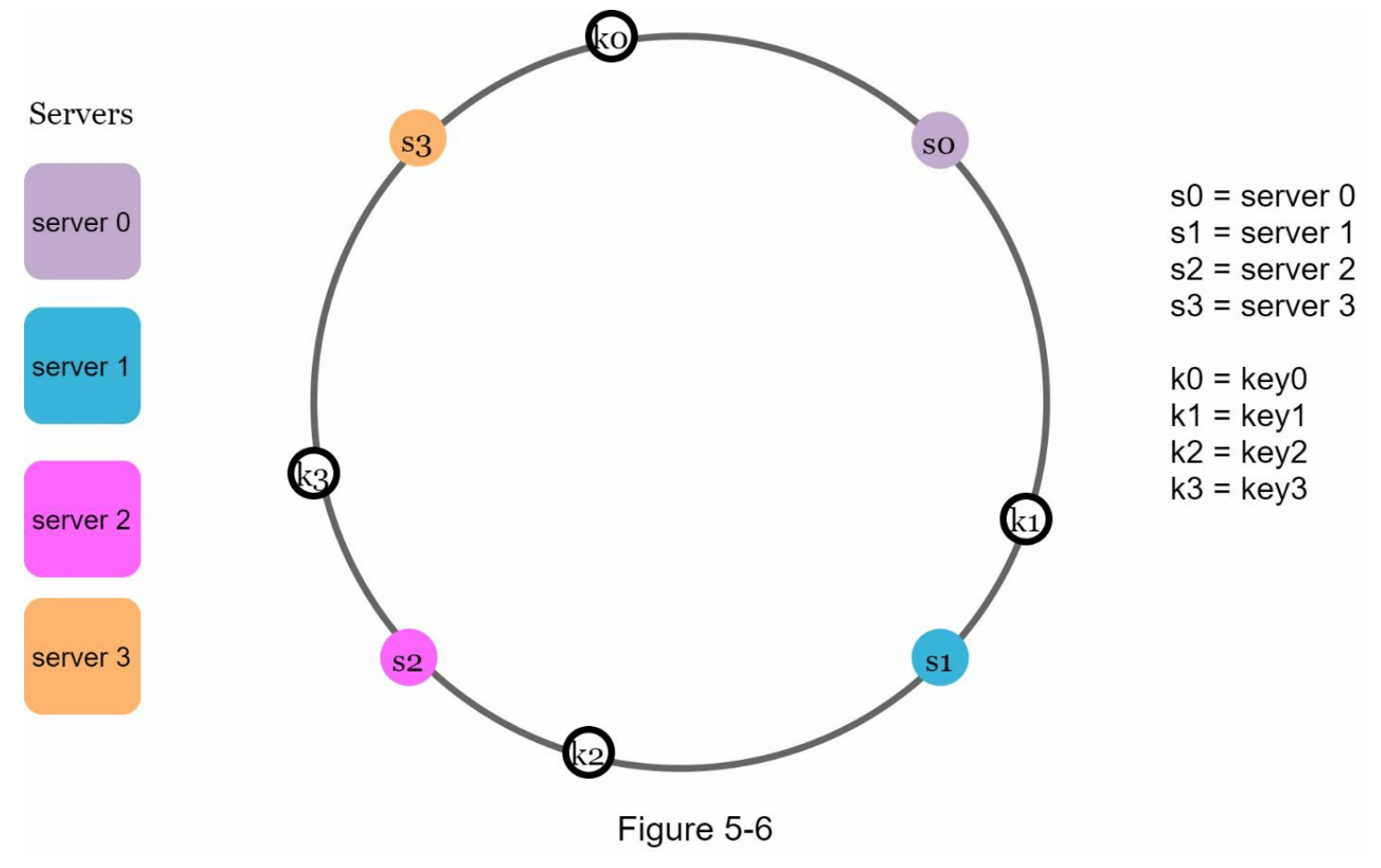
值得注意的是,这里使用的哈希函数与“重哈希问题”中的不同,并且没有使用模运算。正如图 5-6 所示,4 个缓存键(key0、key1、key2 和 key3)被哈希到哈希环上。
服务器查找 (Server lookup)
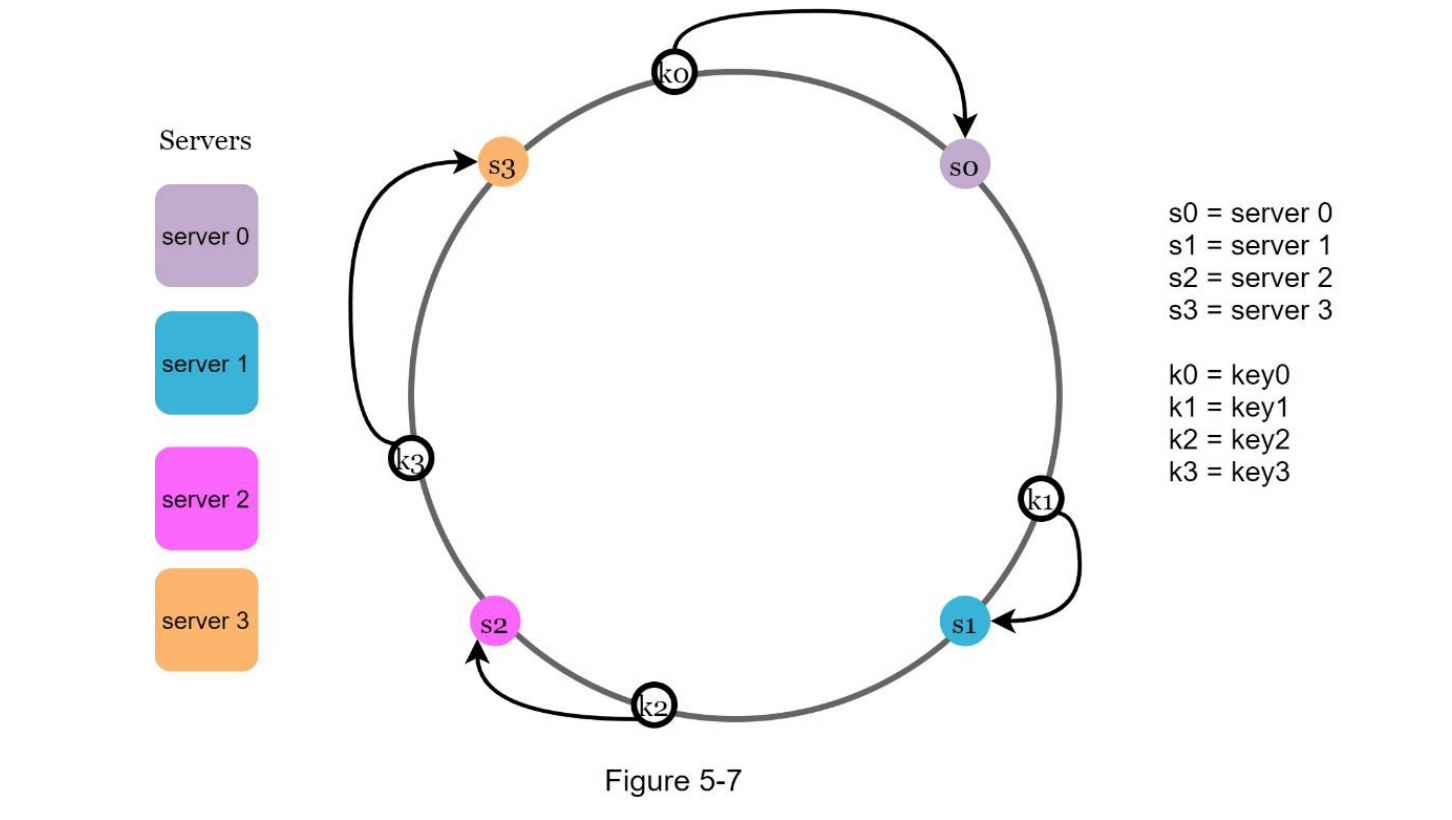
为了确定一个键存储在哪台服务器上,我们从该键在哈希环上的位置开始,顺时针查找直到找到服务器。图 5-7 解释了这个过程。顺时针方向上,key0 存储在服务器0,key1 存储在服务器1,key2 存储在服务器2,key3 存储在服务器3。
添加服务器 (Add a server)
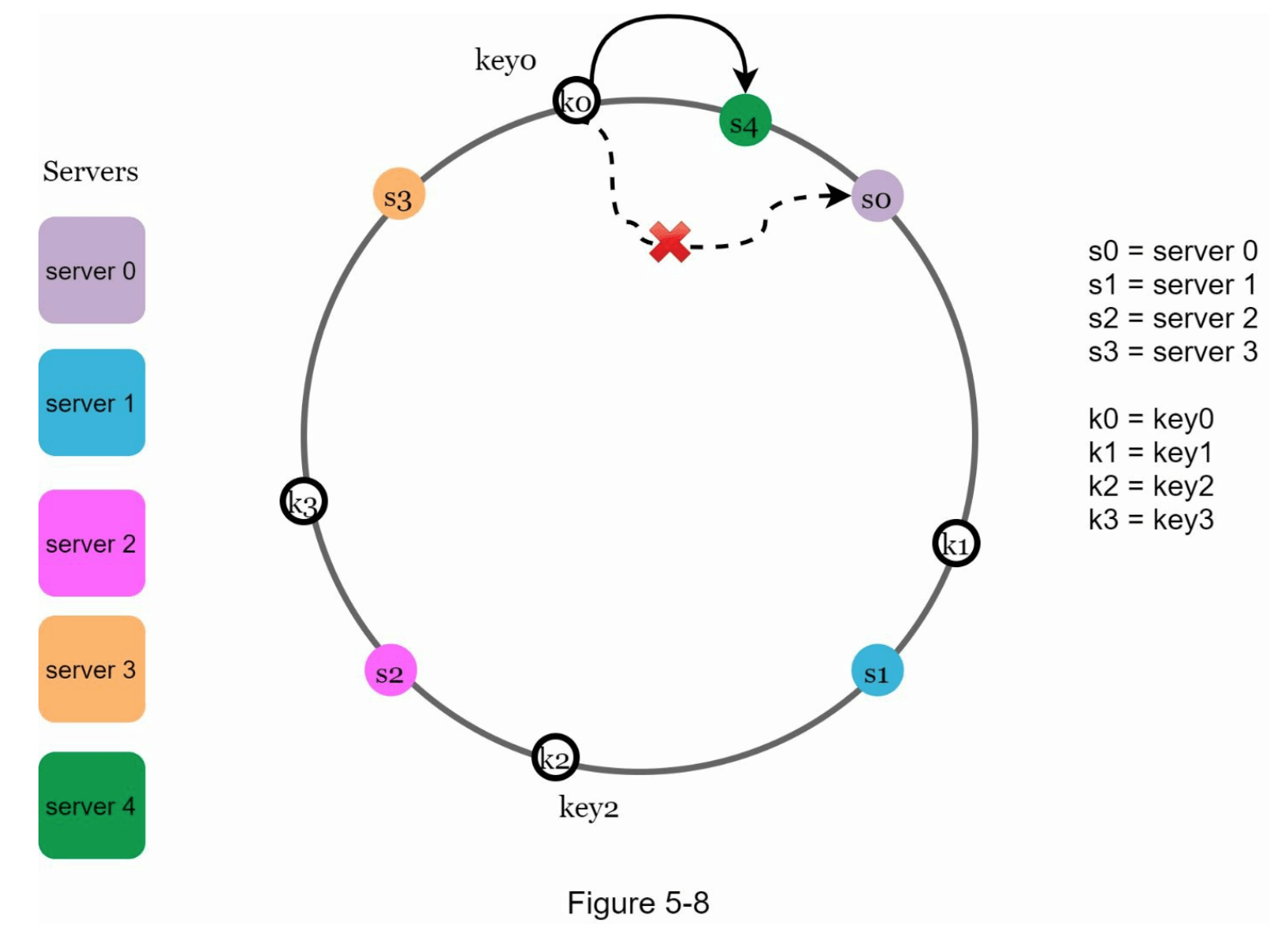
根据上述逻辑,添加新服务器时,只需要重新分配一部分键。在图 5-8 中,添加了新服务器4后,只有 key0 需要重新分配,而 key1、key2 和 key3 仍然保留在相同的服务器上。
让我们仔细看看这个逻辑。在添加服务器4之前,key0 存储在服务器0上。现在,key0 将被存储到服务器4上,因为从 key0 在环上的位置顺时针前进,遇到的第一个服务器是服务器4。其他键根据一致性哈希算法不需要重新分配。
移除服务器 (Remove a server)
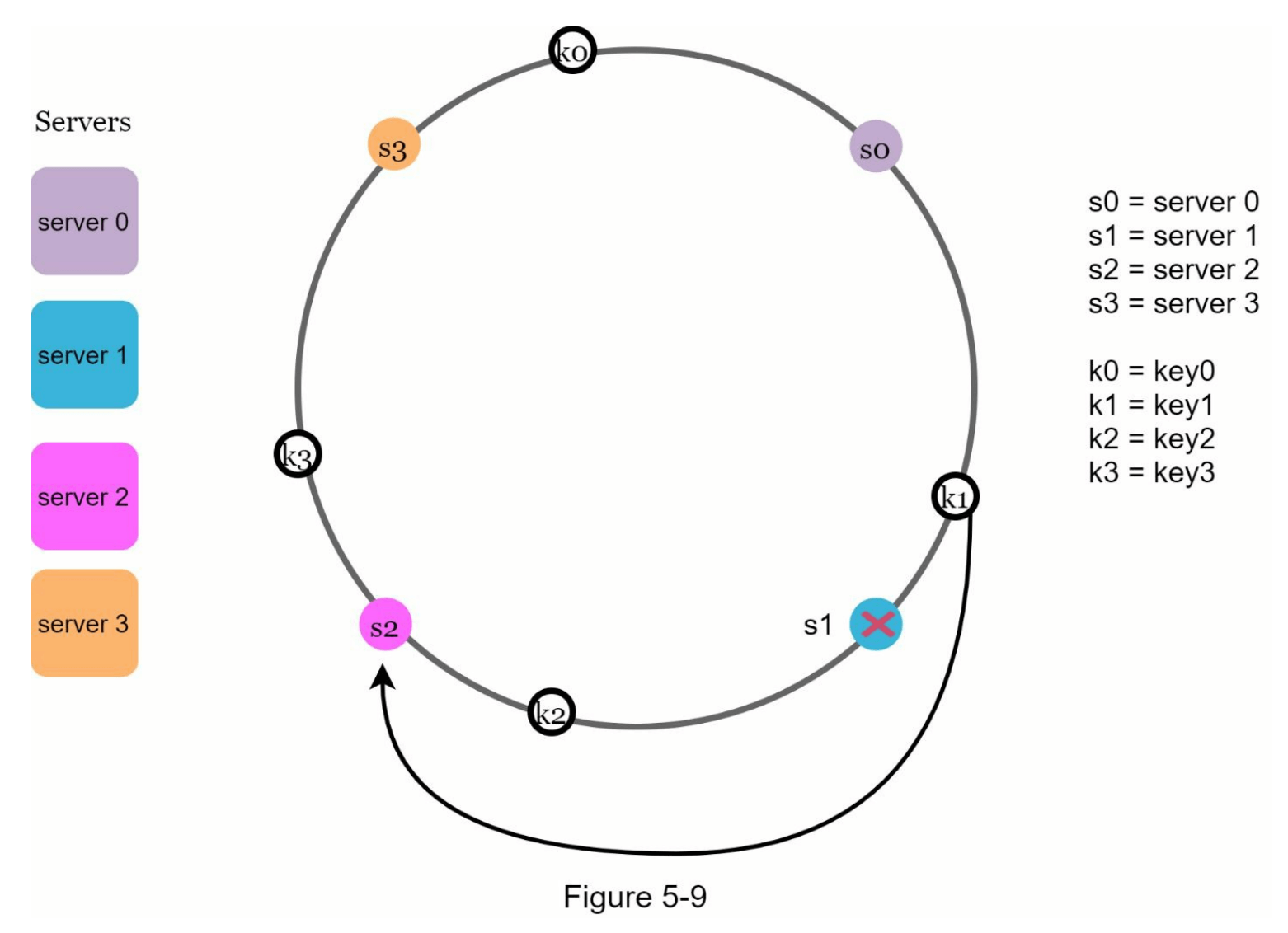
当移除一台服务器时,使用一致性哈希算法只需重新分配一小部分键。在图 5-9 中,当服务器1被移除后,只有 key1 需要重新映射到服务器2,其他键不受影响。
基础方法中的两个问题 (Two issues in the basic approach)
一致性哈希算法由麻省理工学院的 Karger 等人提出 [1]。基本步骤如下:
- 使用均匀分布的哈希函数将服务器和键映射到哈希环上。
- 为了找到某个键被映射到的服务器,从该键的位置顺时针查找,直到找到哈希环上的第一个服务器。
这个方法存在两个问题。
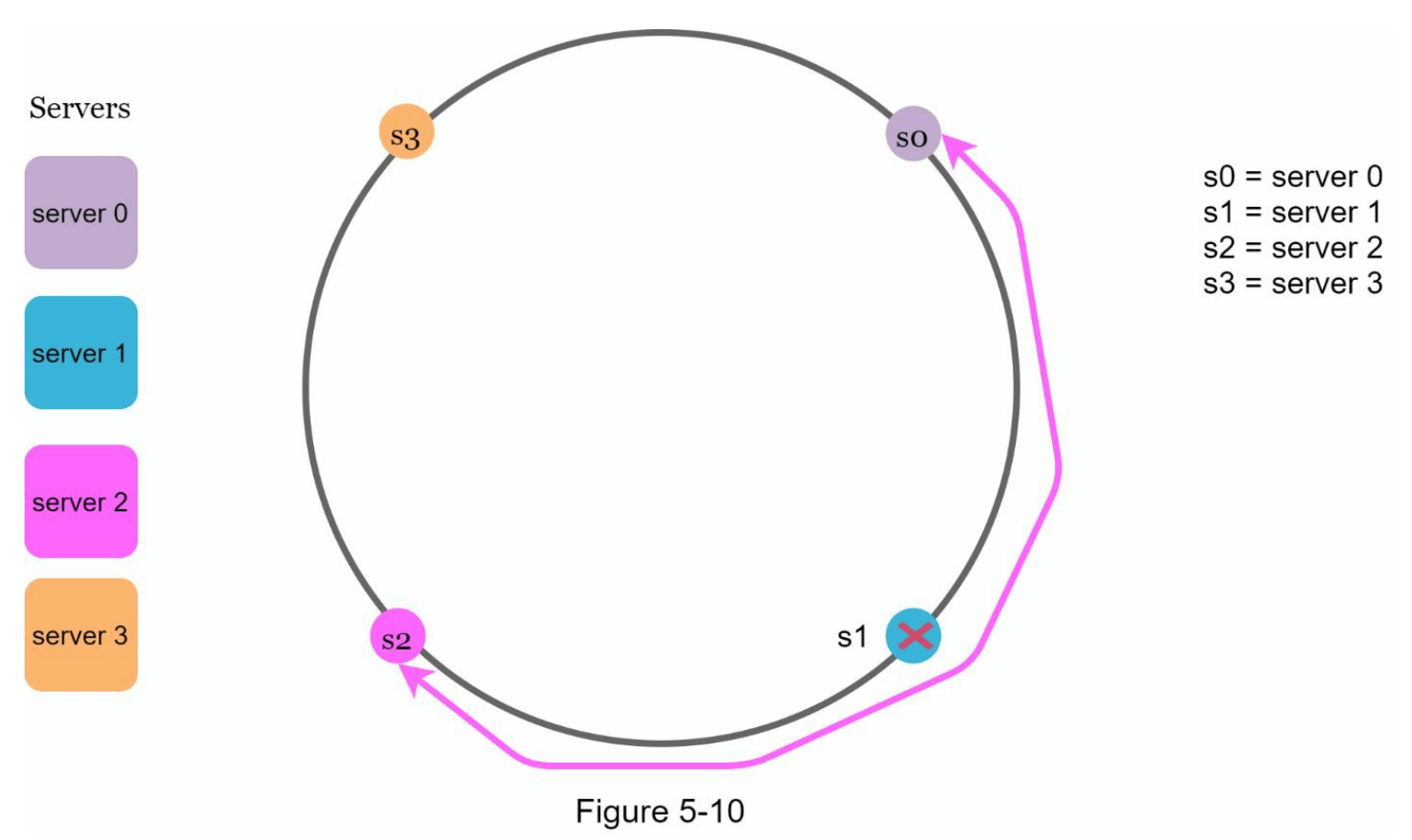
首先,考虑到服务器可能被添加或移除,无法保证所有服务器在环上的分区大小保持相同。分区是指相邻服务器之间的哈希空间。可能会出现每台服务器在环上分配的分区大小非常小或非常大的情况。例如在图 5-10 中,如果 s1 被移除,那么 s2 的分区(用双向箭头标记)将是 s0 和 s3 分区的两倍大。
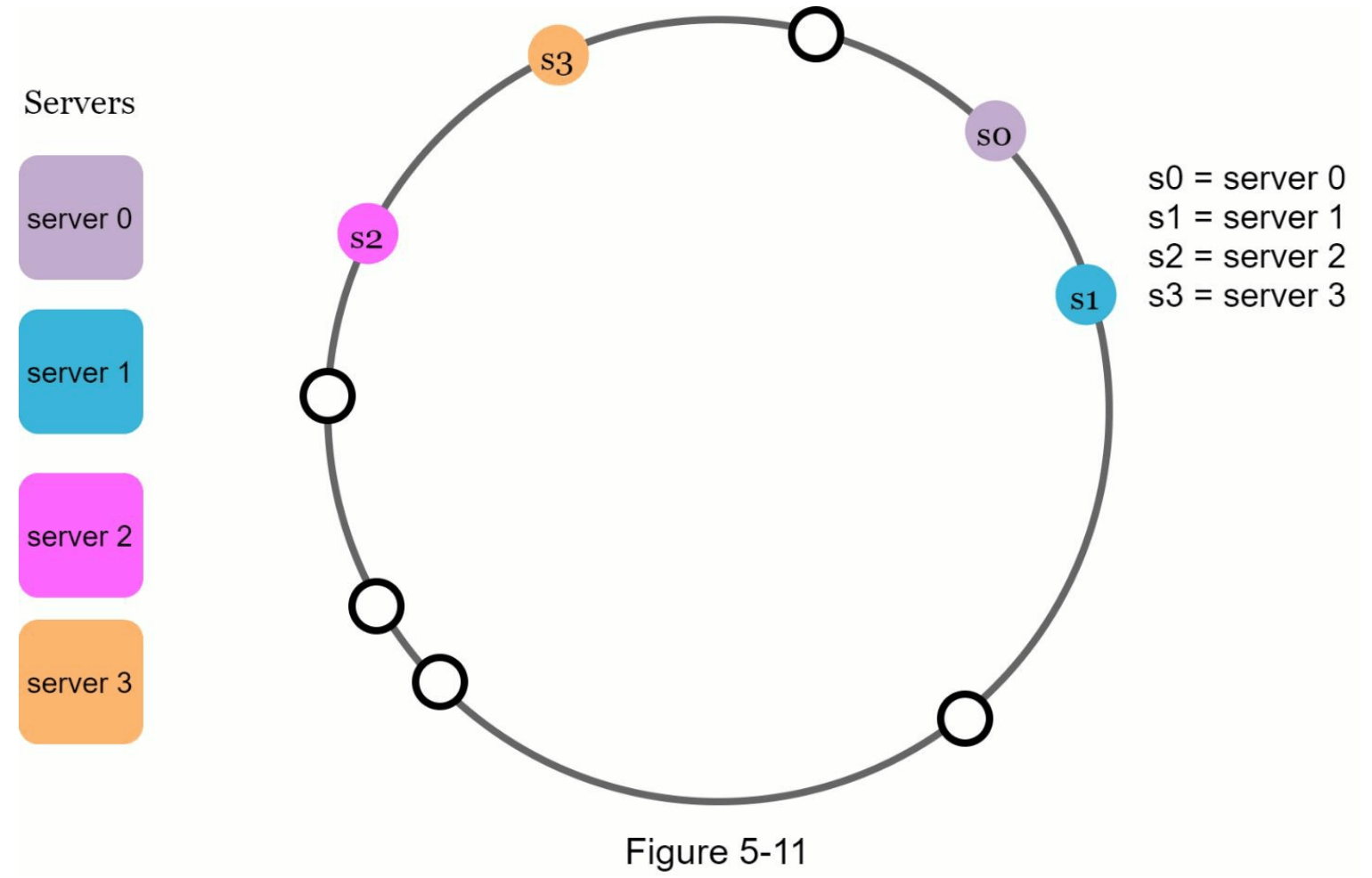
其次,哈希环上可能存在非均匀的键分布。例如,如果服务器映射到图 5-11 中列出的位置信息,大部分键存储在服务器2上,而服务器1和服务器3则没有任何数据。
一种名为虚拟节点(virtual nodes)或副本(replicas)的技术被用来解决这些问题。
虚拟节点 (Virtual nodes)
虚拟节点是指实际节点,每个服务器在哈希环上由多个虚拟节点表示。在图 5-12 中,服务器0和服务器1各有3个虚拟节点。这个数字是任意选择的;在实际系统中,虚拟节点的数量通常会大得多。我们用 s0_0、s0_1 和 s0_2 来表示哈希环上的服务器0,类似地,s1_0、s1_1 和 s1_2 则表示服务器1。通过虚拟节点,每台服务器负责多个分区。标记为 s0 的分区(边)由服务器0管理,而标记为 s1 的分区则由服务器1管理。
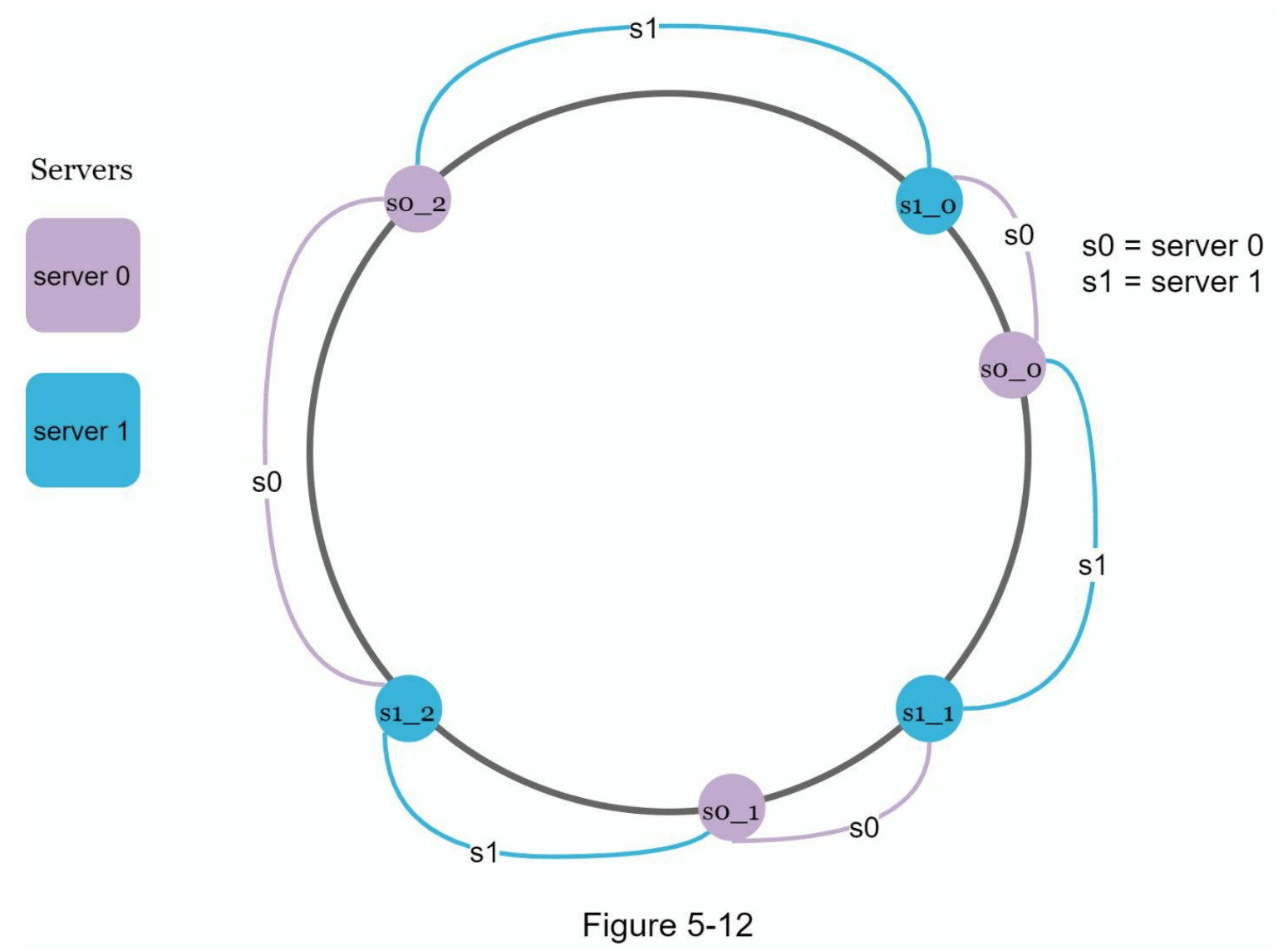
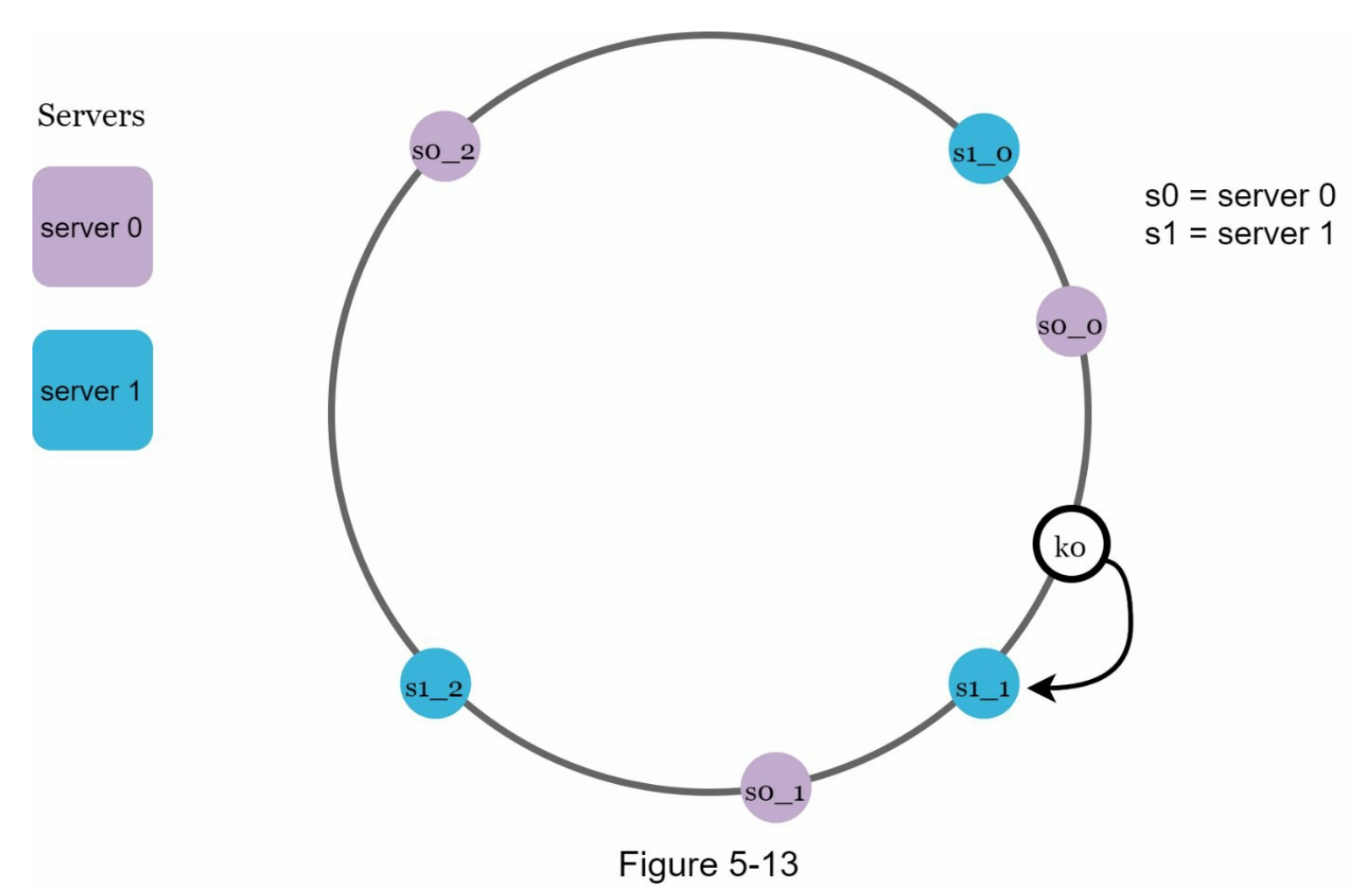
为了找出某个键存储在哪台服务器上,我们从该键的位置顺时针查找,直到找到哈希环上遇到的第一个虚拟节点。在图 5-13 中,若要找出键 k0 存储在哪个服务器上,我们从 k0 的位置顺时针查找,最终找到虚拟节点 s1_1,它对应于服务器1。
随着虚拟节点数量的增加,键的分布变得更加均衡。这是因为随着虚拟节点数量的增多,标准差会变小,从而导致数据分布更加平衡。标准差衡量数据的分散程度。在线研究进行的实验结果 [2] 显示,当虚拟节点数量为一百或两百时,标准差在平均值的5%(200个虚拟节点)和10%(100个虚拟节点)之间。随着虚拟节点数量的增加,标准差会更小。然而,存储虚拟节点所需的数据空间也会增加。这是一个权衡,我们可以根据系统需求调整虚拟节点的数量。
查找受影响的键 (Find affected keys)
当一台服务器被添加或移除时,部分数据需要重新分配。我们如何找到需要重新分配键的受影响范围?
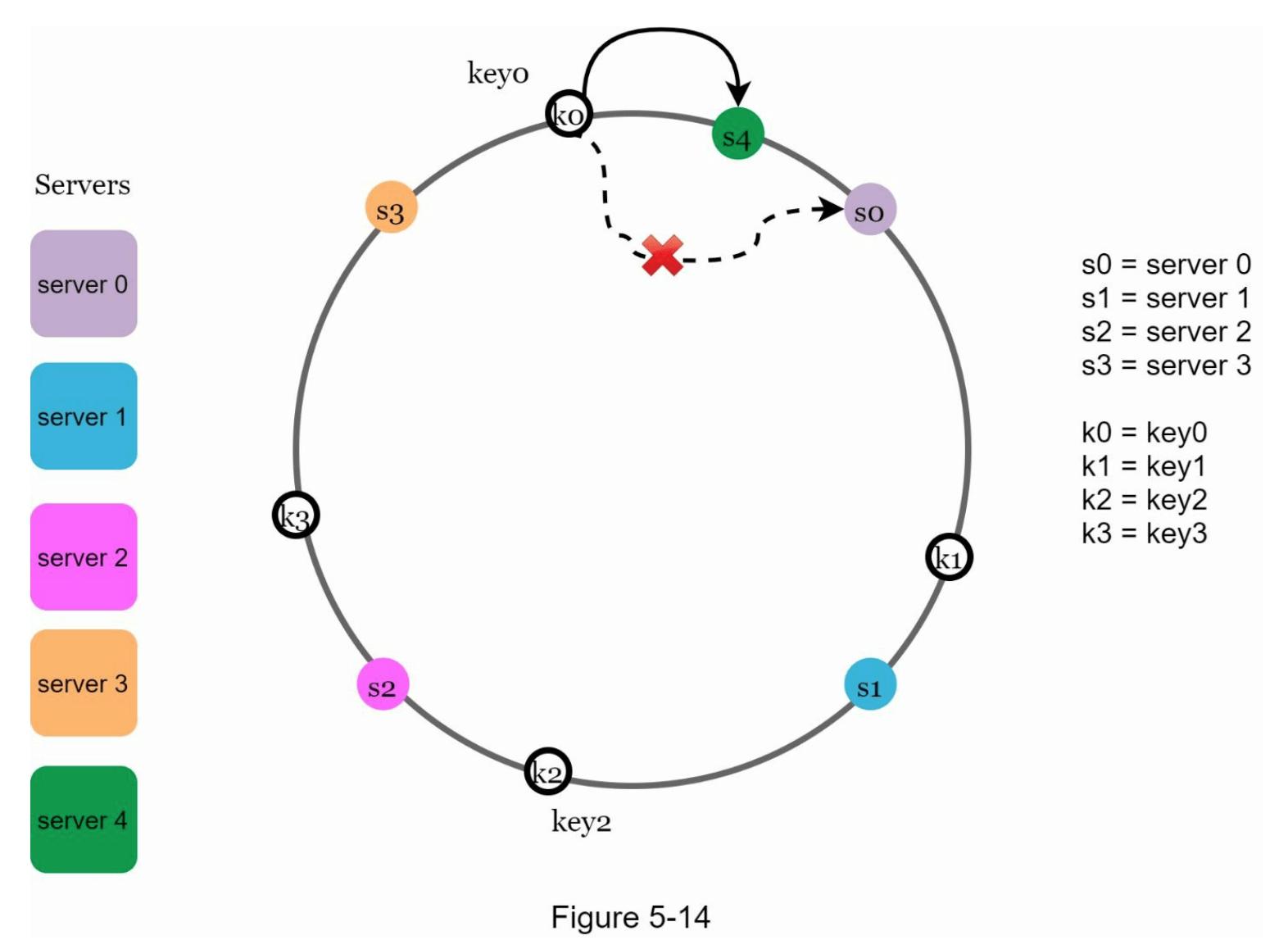
在图 5-14 中,服务器4被添加到哈希环上。受影响的范围从新添加的节点 s4 开始,逆时针方向移动直到找到服务器(s3)。因此,位于 s3 和 s4 之间的键需要重新分配到 s4 上。
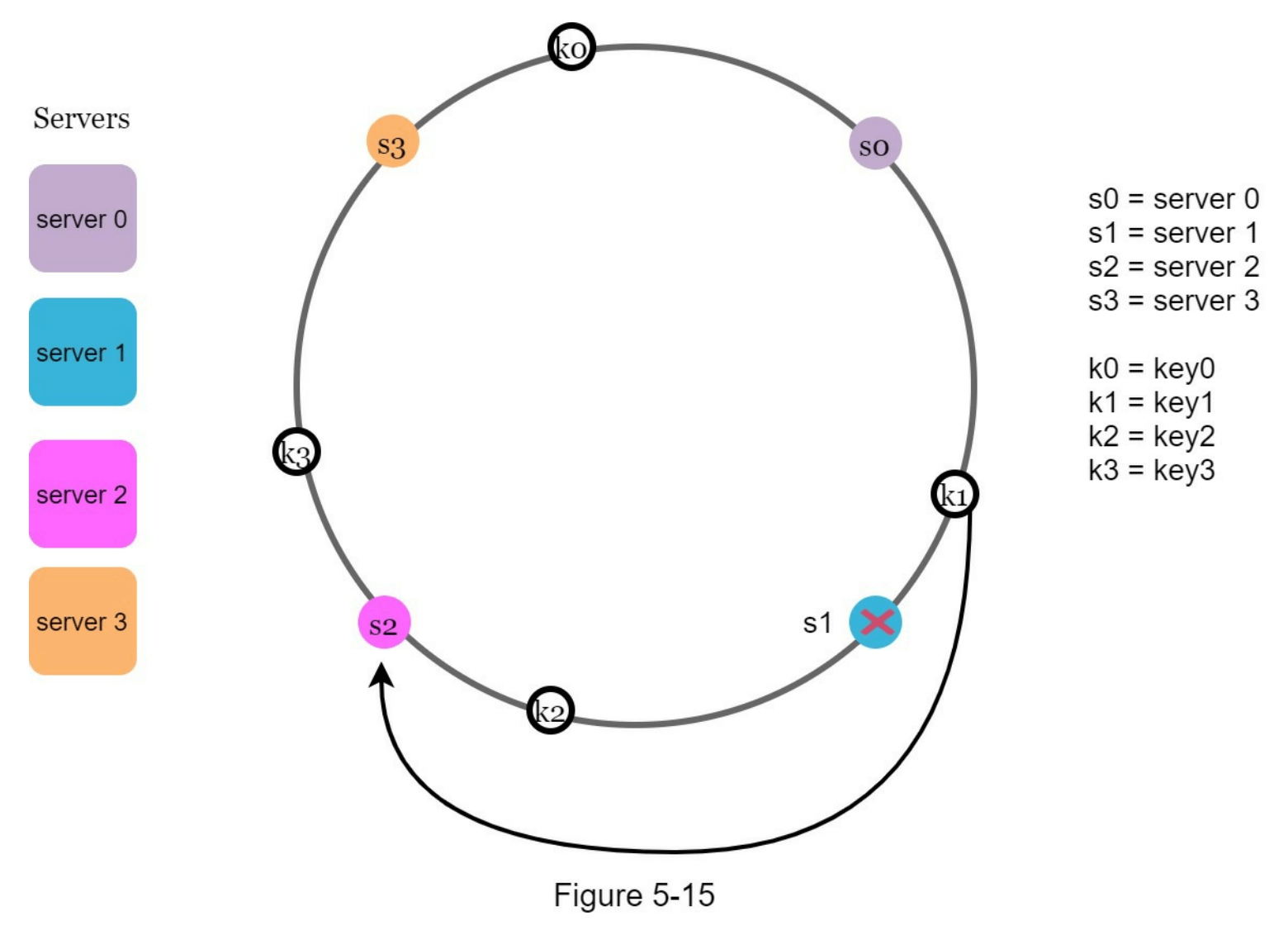
当一台服务器(s1)被移除时,如图 5-15 所示,受影响的范围从移除的节点 s1 开始,逆时针方向移动,直到找到服务器(s0)。因此,位于 s0 和 s1 之间的键必须重新分配到 s2 上。
总结
在本章中,我们深入讨论了一致性哈希,包括它的必要性和工作原理。一致性哈希的好处包括:
- 当添加或移除服务器时,重新分配的键最小化。
- 由于数据更均匀地分布,水平扩展变得更加容易。
- 缓解热点键问题。对特定分片的过度访问可能导致服务器过载。想象一下,Katy Perry、Justin Bieber 和 Lady Gaga 的数据都落在同一个分片上。一致性哈希通过更均匀地分配数据来帮助缓解这一问题。
一致性哈希在实际系统中被广泛使用,包括一些著名的案例:
- 亚马逊 Dynamo 数据库的分区组件 [3]
- Apache Cassandra 中的集群数据分区 [4]
- Discord 聊天应用 [5]
- Akamai 内容分发网络 [6]
- Maglev 网络负载均衡器 [7]
恭喜你读到这里!现在给自己一个赞,做得很好!
参考文献
[1] Consistent hashing: https://en.wikipedia.org/wiki/Consistent_hashing
[2] Consistent Hashing: https://tom-e-white.com/2007/11/consistent-hashing.html
[3] Dynamo: Amazon’s Highly Available Key-value Store: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[4] Cassandra - A Decentralized Structured Storage System: http://www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF
[5] How Discord Scaled Elixir to 5,000,000 Concurrent Users: https://blog.discord.com/scaling-elixir-f9b8e1e7c29b
[6] CS168: The Modern Algorithmic Toolbox Lecture #1: Introduction and Consistent Hashing: http://theory.stanford.edu/~tim/s16/l/l1.pdf
[7] Maglev: A Fast and Reliable Software Network Load Balancer: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44824.pdf