第八章:设计一个 URL 缩短服务 (Design A URL Shortener)
在本章中,我们将解决一个有趣且经典的系统设计面试问题:设计一个像 TinyURL 这样的 URL 缩短服务。
第 1 步 - 理解问题并确定设计范围
系统设计面试问题故意留有开放性。要设计一个精心构建的系统,提出澄清问题至关重要。
候选人:你能举一个 URL 短缩服务的例子吗?
面试官:假设 URL https://www.systeminterview.com/q=chatsystem&c=loggedin&v=v3&l=long 是原始 URL。你的服务创建一个更短的别名:https://tinyurl.com/y7keocwj。如果你点击这个别名,它会重定向到原始 URL。
候选人:流量量级是多少?
面试官:每天生成 1 亿个 URL。
候选人:缩短后的 URL 有多长?
面试官:尽可能短。
候选人:缩短的 URL 中允许使用哪些字符?
面试官:缩短的 URL 可以是数字(0-9)和字母(a-z,A-Z)的组合。
候选人:缩短的 URL 可以被删除或更新吗?
面试官:为了简单起见,我们假设缩短的 URL 不能被删除或更新。
以下是基本用例:
- URL 短缩:给定一个长 URL => 返回一个更短的 URL
- URL 重定向:给定一个短 URL => 重定向到原始 URL
- 高可用性、可扩展性和容错考虑
粗略估算:
- 写操作:每天生成 1 亿个 URL。
- 每秒写操作:
100 million / 24 / 3600 = 1160 - 读操作:假设读操作与写操作的比率为 10:1,读操作每秒:
1160 * 10 = 11600 - 假设 URL 短缩服务运行 10 年,这意味着我们必须支持
100 million × 365 × 10 = 365 billion条记录。 - 假设平均 URL 长度为 100。
- 10 年的存储需求:
365 billion × 100 bytes × 10 years = 365 TB
与面试官一起走过假设和计算过程非常重要,以确保你们双方在同一页面上。
第 2 步 - 提出高层设计并获得认同
在本节中,我们讨论 API 端点、URL 重定向和 URL 短缩流程。
API 端点 (API Endpoints)
API 端点促进客户端与服务器之间的通信。我们将设计 REST 风格的 API。如果您对 RESTful API 不熟悉,可以查阅外部材料,例如参考文献 [1] 中的内容。一个 URL 短缩服务主要需要两个 API 端点。
URL 短缩
要创建一个新的短 URL,客户端发送一个 POST 请求,包含一个参数:原始长 URL。API 的格式如下:POST api/v1/data/shorten- 请求参数:
{longUrl: longURLString} - 返回:
shortURL
- 请求参数:
URL 重定向
要将短 URL 重定向到相应的长 URL,客户端发送一个 GET 请求。API 的格式如下:GET api/v1/shortUrl- 返回:用于 HTTP 重定向的
longURL
- 返回:用于 HTTP 重定向的
URL 重定向 (URL redirecting)
图 8-1 展示了在浏览器中输入 tinyurl 时发生的情况。一旦服务器收到 tinyurl 请求,它会通过 301 重定向将短 URL 转换为长 URL。
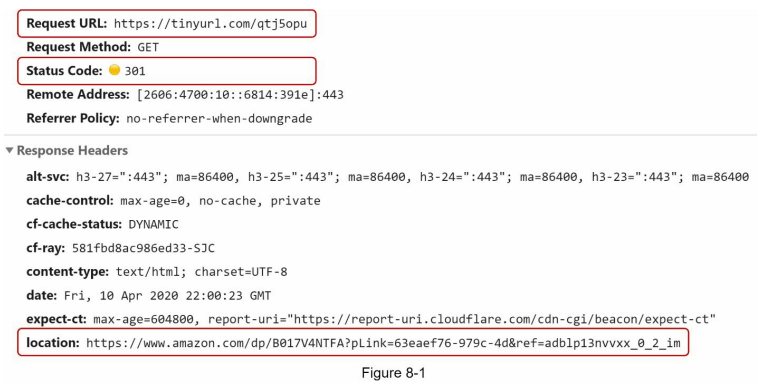
客户端与服务器之间的详细通信如图 8-2 所示。
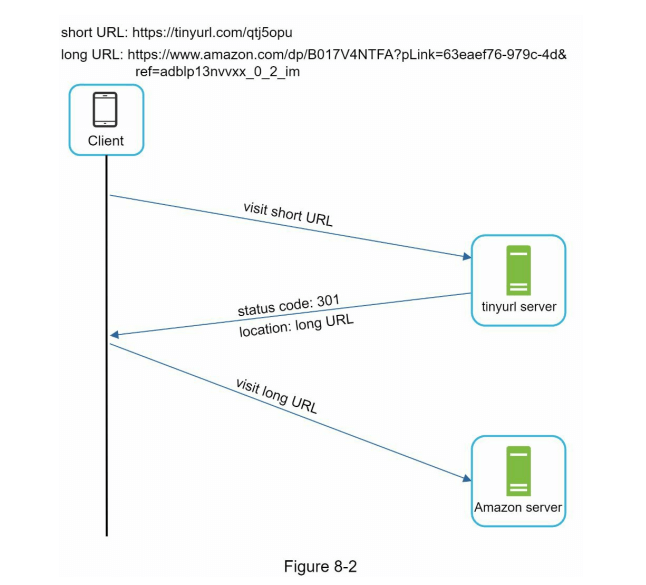
这里值得讨论的一点是 301 重定向与 302 重定向之间的区别。
301 重定向
301 重定向表示请求的 URL 已“永久”移动到长 URL。由于是永久重定向,浏览器会缓存响应,对于同一 URL 的后续请求将不会再发送到 URL 短缩服务。相反,请求将直接重定向到长 URL 服务器。
302 重定向
302 重定向意味着 URL 已“临时”移动到长 URL,这意味着对于同一 URL 的后续请求将首先发送到 URL 短缩服务。然后,它们会被重定向到长 URL 服务器。
每种重定向方法都有其优缺点。如果优先考虑减少服务器负载,那么使用 301 重定向是有意义的,因为同一 URL 只有第一次请求会发送到 URL 短缩服务器。然而,如果分析数据很重要,302 重定向会是更好的选择,因为它更容易跟踪点击率和点击来源。
实现 URL 重定向的最直观的方法是使用哈希表。假设哈希表存储 <shortURL, longURL> 对,URL 重定向可以通过以下方式实现:
- 获取长 URL:
longURL = hashTable.get(shortURL) - 一旦获取到长 URL,执行 URL 重定向。
URL 短缩 (URL shortening)
假设短 URL 的格式如下:www.tinyurl.com/{hashValue}。为了支持 URL 短缩的用例,我们必须找到一个哈希函数 f(x),将长 URL 映射到 hashValue,如图 8-3 所示。
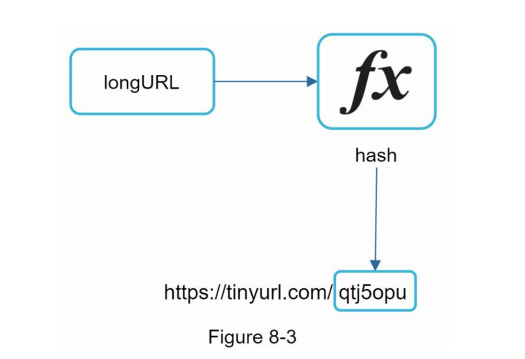
哈希函数必须满足以下要求:
- 每个
longURL必须被哈希为一个hashValue。 - 每个
hashValue都可以映射回其对应的longURL。
关于哈希函数的详细设计将在深入讨论中进行。
第 3 步 - 设计深入探讨
到目前为止,我们已经讨论了 URL 短缩和 URL 重定向的高层设计。在本节中,我们将深入探讨以下内容:数据模型、哈希函数、URL 短缩和 URL 重定向。
数据模型 (Data model)
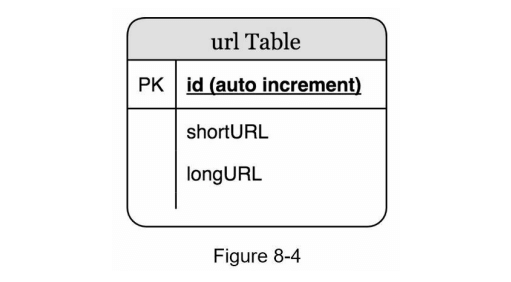
在高层设计中,所有内容都存储在哈希表中。这是一个很好的起点;然而,这种方法在现实世界的系统中并不可行,因为内存资源是有限且昂贵的。一个更好的选择是将 <shortURL, longURL> 映射存储在关系数据库中。图 8-4 显示了一个简单的数据库表设计。该表的简化版本包含 3 列:id、shortURL 和 longURL。
哈希函数 (Hash function)
哈希函数用于将长 URL 哈希为短 URL,也称为 hashValue。
哈希值长度hashValue 由字符 [0-9, a-z, A-Z] 组成,共有 10 + 26 + 26 = 62 个可能字符。为了确定 hashValue 的长度,需要找到最小的 n,使得 62^n >= 365亿。根据背面的估算,系统必须支持多达 365 亿个 URL。表 8-1 显示了 hashValue 的长度及其所能支持的最大 URL 数量。
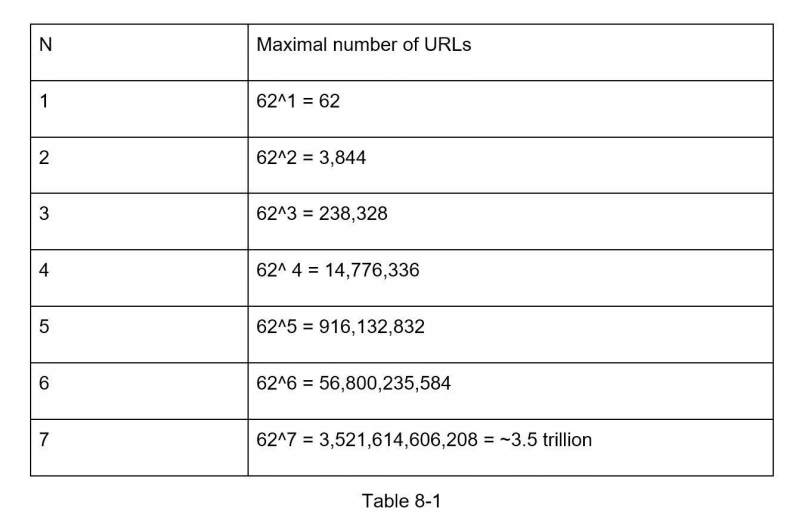
当 n = 7 时,62^n ≈ 3.5 万亿,3.5 万亿远远足够容纳 365 亿个 URL,因此 hashValue 的长度为 7。
我们将探讨两种类型的哈希函数,用于 URL 短缩。第一种是“哈希 + 碰撞解决”,第二种是“基于 62 的转换”。让我们逐一看一下它们。
哈希 + 碰撞解决
为了缩短长 URL,我们应该实现一个将长 URL 哈希为 7 个字符字符串的哈希函数。一个简单的解决方案是使用广为人知的哈希函数,如 CRC32、MD5 或 SHA-1。以下表格比较了在此 URL(https://en.wikipedia.org/wiki/Systems_design)上应用不同哈希函数后的哈希结果。
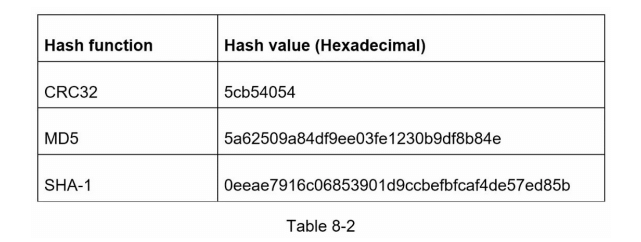
如表 8-2 所示,即使是最短的哈希值(来自 CRC32)也太长(超过 7 个字符)。我们该如何缩短它呢?
第一种方法是收集哈希值的前 7 个字符;然而,这种方法可能导致哈希碰撞。为了解决哈希碰撞,我们可以递归地附加一个新的预定义字符串,直到不再发现碰撞。该过程如图 8-5 所示。
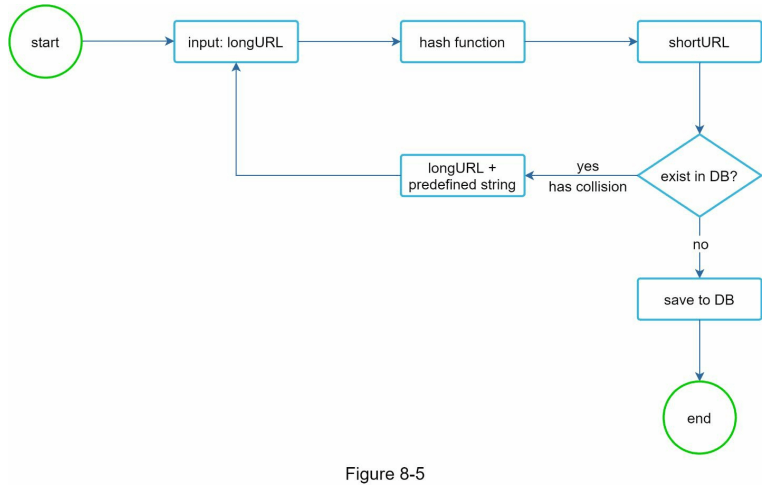
这种方法可以消除碰撞;然而,对于每个请求查询数据库以检查短 URL 是否存在的成本很高。一种名为布隆过滤器(Bloom Filters)的方法可以提高性能。布隆过滤器是一种节省空间的概率性技术,用于测试一个元素是否属于某个集合。有关更多详细信息,请参考参考材料 [2]。
基于 62 的转换
基于 62 的转换是 URL 短缩器常用的另一种方法。基数转换用于在不同的数字表示系统之间转换相同的数字。由于 hashValue 有 62 个可能的字符,因此使用基于 62 的转换。让我们用一个例子来解释转换是如何工作的:将 1115710 转换为基数 62 表示法(1115710 表示的是 11157 在基数 10 系统中的值)。
- 从名字可以看出,基数 62 是一种使用 62 个字符进行编码的方法。其映射关系为:
- 0-0, ..., 9-9, 10-a, 11-b, ..., 35-z, 36-A, ..., 61-Z, 其中 ‘a’ 代表 10,‘Z’ 代表 61,等等。
- 1115710 = 2 x 622 + 55 x 621 + 59 x 620 = [2, 55, 59] -> [2, T, X] 在基数 62 表示法中
图 8-6 展示了这一转换过程。

- 因此,短 URL 为 https://tinyurl.com/2TX。
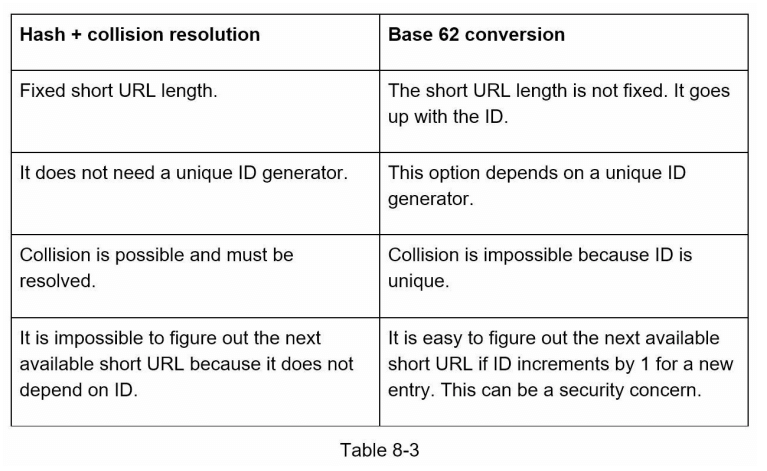
两种方法的比较
表 8-3 显示了这两种方法的不同之处。
URL 短缩流程深入分析
作为系统的核心组成部分,我们希望 URL 短缩流程在逻辑上保持简单且功能齐全。在我们的设计中使用了基于 62 的转换。我们构建了以下图表(图 8-7)以演示这个流程。
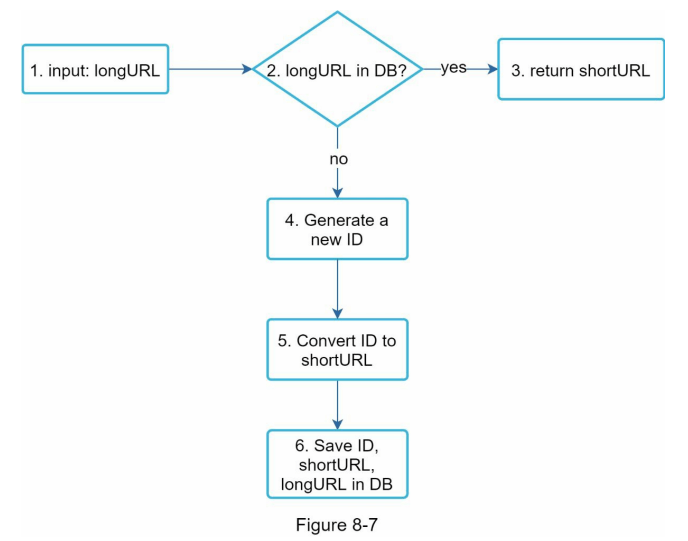
longURL 是输入。
系统检查 longURL 是否在数据库中。
如果存在,说明 longURL 之前已转换为 shortURL。在这种情况下,从数据库中获取 shortURL 并返回给客户端。
如果不存在,则 longURL 是新的。由唯一 ID 生成器生成一个新的唯一 ID(主键)。
使用基于 62 的转换将 ID 转换为 shortURL。
创建一个新的数据库行,包括 ID、shortURL 和 longURL。
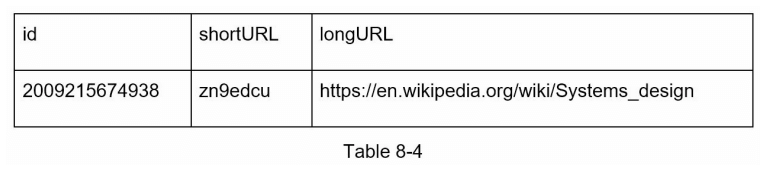
为了使流程更容易理解,我们来看一个具体的例子:
- 假设输入的 longURL 是:
https://en.wikipedia.org/wiki/Systems_design - 唯一 ID 生成器返回的 ID 是:
2009215674938。 - 使用基于 62 的转换将 ID 转换为 shortURL。ID(
2009215674938)被转换为“zn9edcu”。 - 将 ID、shortURL 和 longURL 保存到数据库中,如表 8-4 所示。
值得一提的是分布式唯一 ID 生成器。它的主要功能是生成全局唯一的 ID,这些 ID 用于创建 shortURL。在高度分布式的环境中,实现唯一 ID 生成器是具有挑战性的。幸运的是,我们在“第 7 章:设计分布式系统中的唯一 ID 生成器”中已经讨论了一些解决方案。你可以回顾一下以刷新你的记忆。
URL 重定向深度分析
图 8-8 显示了 URL 重定向的详细设计。由于读请求比写请求多,<shortURL, longURL> 的映射被存储在缓存中以提高性能。
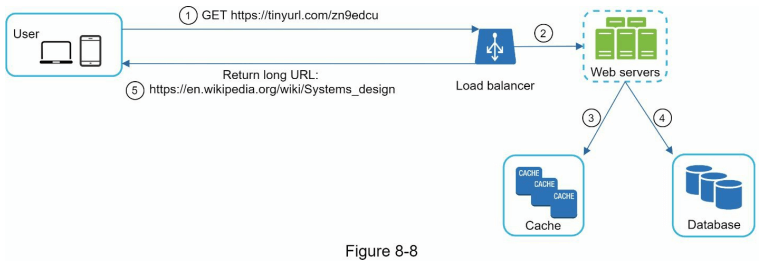
URL 重定向的流程总结如下:
用户点击短 URL 链接:
https://tinyurl.com/zn9edcu。负载均衡器将请求转发给 Web 服务器。
如果短 URL 已经在缓存中,则直接返回 longURL。
如果短 URL 不在缓存中,则从数据库中获取 longURL。如果它不在数据库中,可能是用户输入了无效的短 URL。
将 longURL 返回给用户。
第 4 步 - 总结
在本章中,我们讨论了 API 设计、数据模型、哈希函数、URL 缩短和 URL 重定向。
如果在面试结束时还有额外时间,以下是一些补充讨论要点:
速率限制器:我们可能面临的一个潜在安全问题是恶意用户发送大量的 URL 缩短请求。速率限制器有助于根据 IP 地址或其他过滤规则来筛选请求。如果想要回顾速率限制的内容,请参见“第 4 章:设计速率限制器”。
Web 服务器扩展:由于 Web 层是无状态的,通过添加或移除 Web 服务器来扩展 Web 层是非常简单的。
数据库扩展:数据库复制和分片是常见的扩展技术。
分析:数据对于业务成功越来越重要。将分析解决方案集成到 URL 缩短器中可以帮助回答一些重要问题,比如有多少人点击了链接?他们何时点击链接?等等。
可用性、一致性和可靠性:这些概念是任何大型系统成功的核心。我们在第 1 章中详细讨论过这些主题,请回顾一下相关内容。
恭喜你能走到这一步!现在给自己一个赞吧。干得好!
参考文献
[1] A RESTful Tutorial: https://www.restapitutorial.com/index.html
[2] Bloom filter: https://en.wikipedia.org/wiki/Bloom_filter