第十五章:设计 Google Drive
近年来,云存储服务如Google Drive、Dropbox、Microsoft OneDrive和Apple iCloud变得非常流行。在本章中,您将被要求设计Google Drive。
在开始设计之前,让我们先花一点时间了解Google Drive。Google Drive是一个文件存储和同步服务,帮助您在云中存储文档、照片、视频和其他文件。您可以从任何计算机、智能手机和平板电脑访问您的文件。您可以轻松地与朋友、家人和同事共享这些文件 [1]。图15-1和图15-2展示了Google Drive在浏览器和移动应用中的外观。
第 1 步 - 理解问题并建立设计范围
设计一个Google Drive是一个大项目,因此重要的是提出问题以缩小范围。
候选人:最重要的功能是什么?
面试官:上传和下载文件、文件同步以及通知。
候选人:这是一个移动应用、网页应用还是两者都有?
面试官:两者都有。
候选人:支持哪些文件格式?
面试官:任何文件类型。
候选人:文件需要加密吗?
面试官:是的,存储中的文件必须加密。
候选人:文件大小有限制吗?
面试官:是的,文件必须小于10 GB。
候选人:产品有多少用户?
面试官:1000万日活跃用户(DAU)。
在本章中,我们关注以下功能:
- 添加文件:添加文件的最简单方式是将文件拖放到Google Drive中。
- 下载文件。
- 在多个设备间同步文件:当一个设备上添加文件时,文件会自动同步到其他设备。
- 查看文件版本。
- 与朋友、家人和同事共享文件。
- 在文件被编辑、删除或与您共享时发送通知。
本章未讨论的功能包括:
- Google文档编辑和协作:Google文档允许多人同时编辑同一文档。这不在我们的设计范围内。
除了明确需求外,了解非功能性需求也很重要:
- 可靠性:对于存储系统,可靠性至关重要。数据丢失是不可接受的。
- 快速同步速度:如果文件同步耗时过长,用户会变得不耐烦并放弃该产品。
- 带宽使用:如果产品占用大量不必要的网络带宽,用户会不满,尤其是在使用移动数据计划时。
- 可扩展性:系统应能够处理高流量。
- 高可用性:当某些服务器离线、速度变慢或发生意外网络错误时,用户仍应能够使用系统。
粗略估算
- 假设应用有5000万注册用户和1000万日活跃用户。
- 用户获得10 GB的免费存储空间。
- 假设用户每天上传2个文件。平均文件大小为500 KB。
- 读写比例为1:1。
- 总分配空间:5000万 * 10 GB = 500 PB。
- 上传API的每秒查询数(QPS):1000万 * 2次上传 / 24小时 / 3600秒 = ~240。
- 峰值QPS = QPS * 2 = 480。
第 2 步 - 提出高层设计并获得认可
我们将采用一种略微不同的方法,而不是一开始就展示高层设计图。我们将从一个简单的开始:在单个服务器上构建一切。然后,逐步扩展以支持数百万用户。通过这种练习,可以帮助您回忆起书中讨论的一些重要主题。
让我们从单服务器设置开始,如下所示:
- 一个Web服务器,用于上传和下载文件。
- 一个数据库,用于跟踪元数据,如用户数据、登录信息、文件信息等。
- 一个存储系统,用于存储文件。我们分配1TB的存储空间来存储文件。
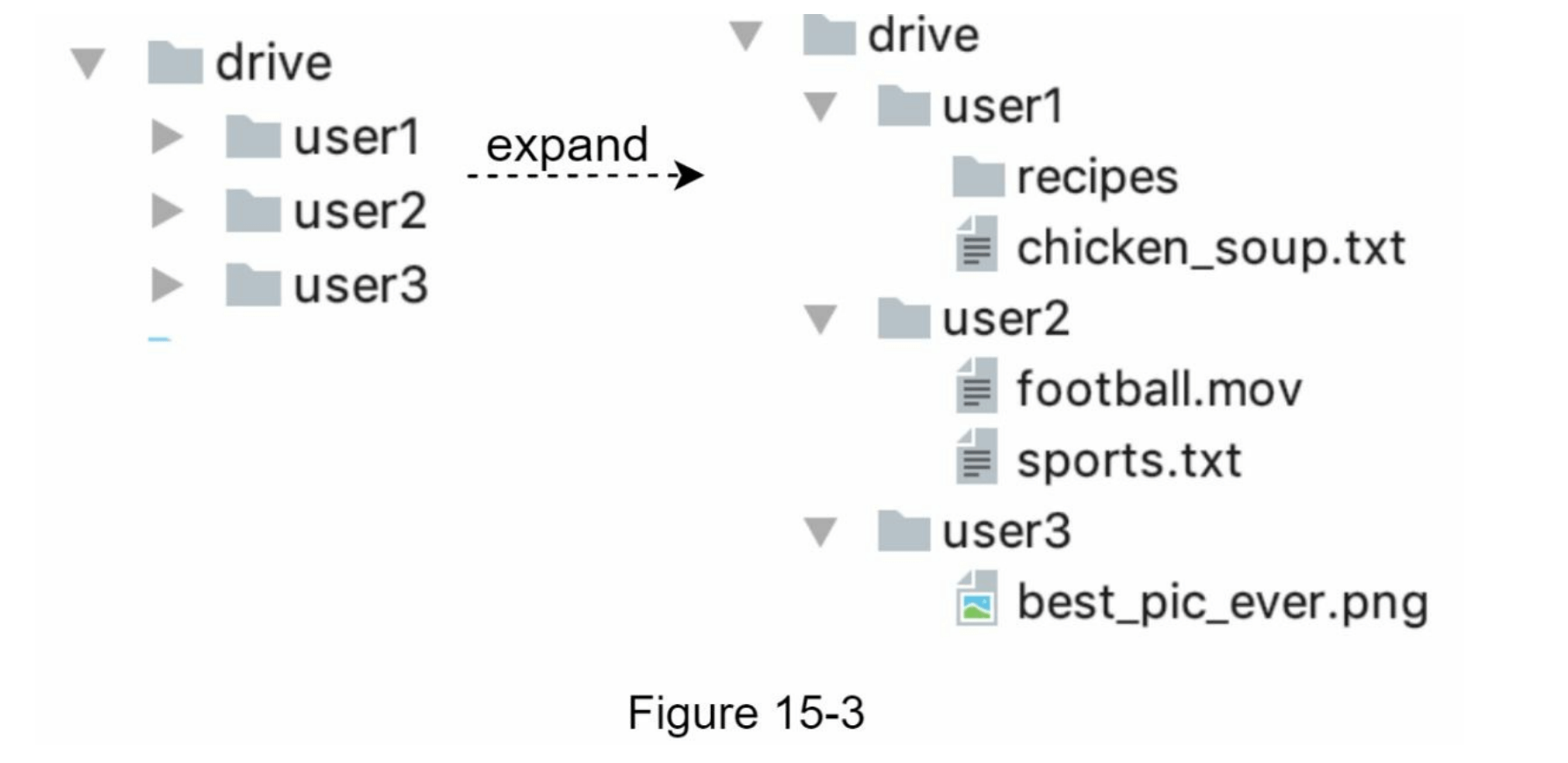
我们花了几个小时设置Apache Web服务器、MySQL数据库以及一个名为drive/的目录,作为存储上传文件的根目录。在drive/目录下,有一个目录列表,称为命名空间。每个命名空间包含该用户上传的所有文件。服务器上的文件名与原始文件名保持一致。每个文件或文件夹可以通过连接命名空间和相对路径唯一标识。
图15-3展示了/drive目录的左侧示例及其右侧的展开视图。
APIs
API的设计是什么样的?我们主要需要三个API:上传文件、下载文件和获取文件版本。
上传文件到Google Drive 支持两种类型的上传:
- 简单上传:当文件大小较小时使用此上传类型。
- 可恢复上传:当文件大小较大且网络中断的可能性较高时使用此上传类型。
可恢复上传API示例:
https://api.example.com/files/upload?uploadType=resumable参数:
uploadType=resumabledata:要上传的本地文件。
可恢复上传通过以下三步实现 [2]:
- 发送初始请求以检索可恢复的URL。
- 上传数据并监控上传状态。
- 如果上传受到干扰,恢复上传。
从Google Drive下载文件 示例API:
https://api.example.com/files/download参数:
path:下载文件的路径。
示例参数:
json{ "path": "/recipes/soup/best_soup.txt" }获取文件版本 示例API:
https://api.example.com/files/list_revisions参数:
path:您想获取版本历史记录的文件路径。limit:返回的最大版本数。
示例参数:
json{ "path": "/recipes/soup/best_soup.txt", "limit": 20 }
所有API都需要用户身份验证,并使用HTTPS。安全套接层(SSL)保护客户端与后端服务器之间的数据传输。
从单服务器迁移
随着上传的文件增多,最终会收到空间不足的警告,如图15-4所示。

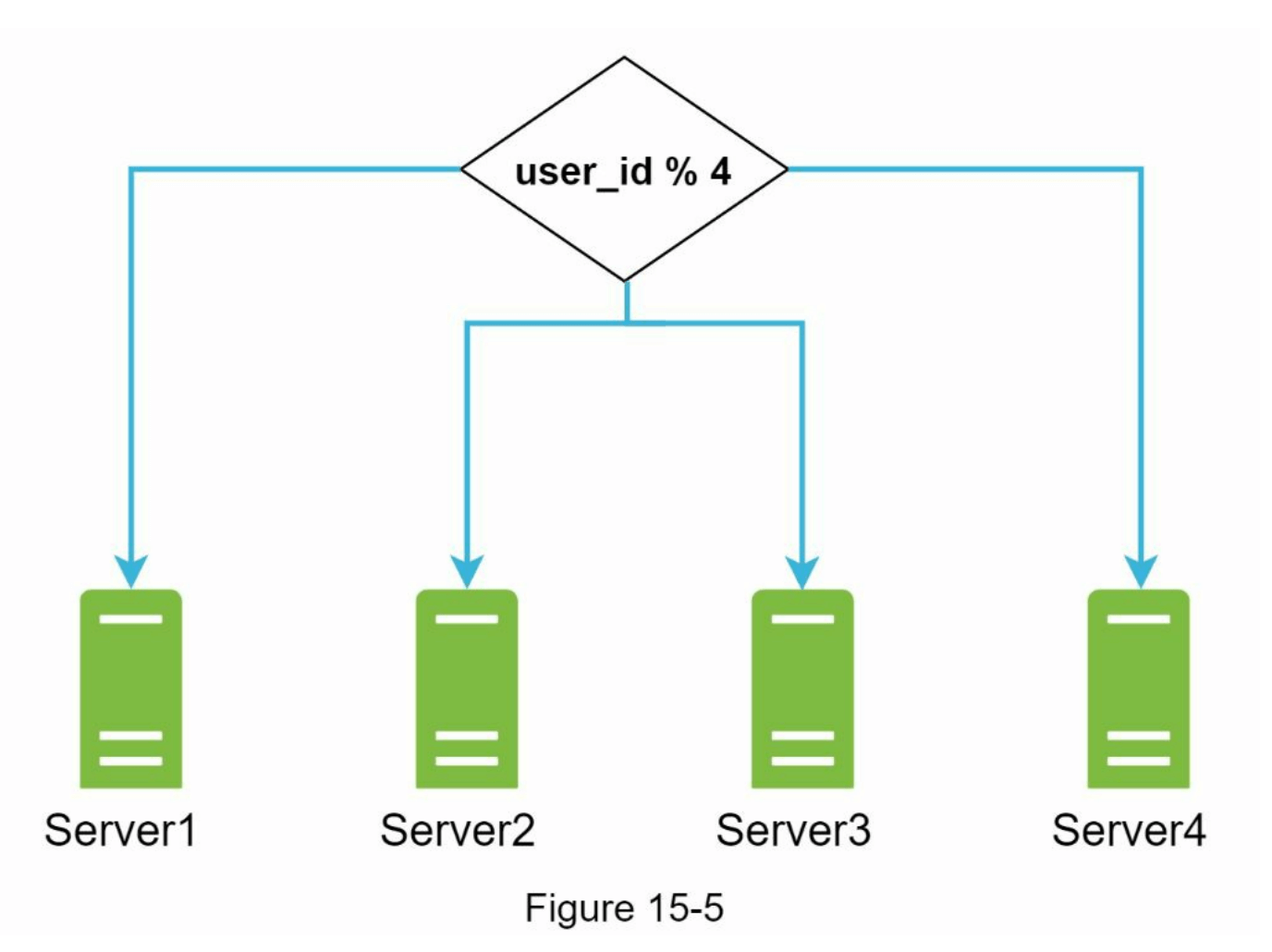
只有10MB的存储空间剩余!这是一个紧急情况,因为用户无法再上传文件。第一个想到的解决方案是对数据进行分片,以便将其存储在多个存储服务器上。图15-5展示了基于user_id的分片示例。
你通宵达旦地设置了数据库分片并密切监控,一切又恢复正常。你已扑灭了这场火灾,但仍然担心在存储服务器出现故障时可能会造成数据丢失。你问了问你的后端专家朋友Frank,他告诉你许多领先公司(如Netflix和Airbnb)都使用Amazon S3进行存储。“Amazon简单存储服务(Amazon S3)是一种对象存储服务,提供行业领先的可扩展性、数据可用性、安全性和性能” [3]。你决定进行一些研究,看看这是否适合。
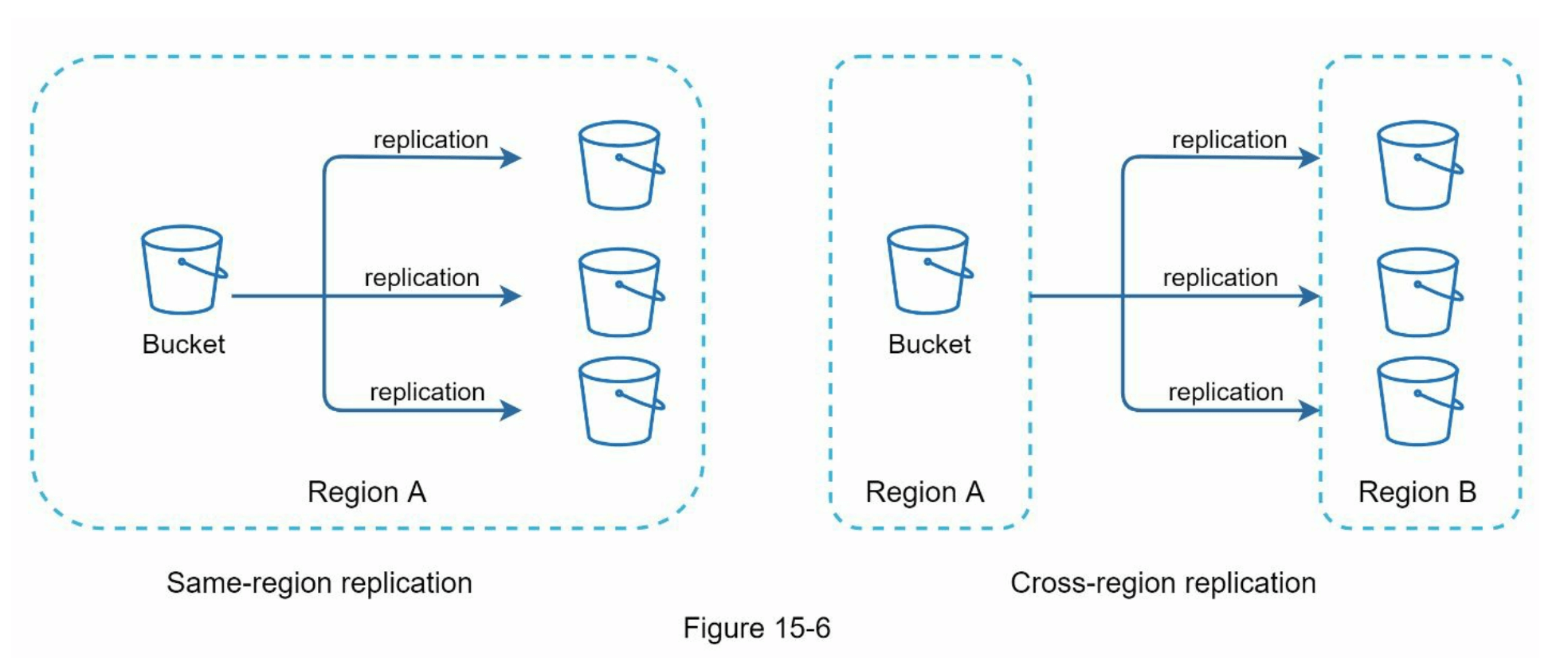
经过大量阅读,你对S3存储系统有了良好的理解,并决定将文件存储在S3中。Amazon S3支持同一区域和跨区域复制。区域是Amazon Web Services(AWS)拥有数据中心的地理区域。如图15-6所示,数据可以在同一区域(左侧)和跨区域(右侧)进行复制。冗余文件存储在多个区域,以防止数据丢失并确保可用性。存储桶类似于文件系统中的文件夹。
将文件放入S3后,你终于可以安心睡觉,不用担心数据丢失。为了防止未来发生类似问题,你决定进一步研究可以改进的领域。以下是你发现的一些领域:
- 负载均衡器:添加负载均衡器以分配网络流量。负载均衡器确保流量均匀分配,如果某个Web服务器宕机,它将重新分配流量。
- Web服务器:在添加负载均衡器后,可以根据流量负载轻松增加/删除更多Web服务器。
- 元数据数据库:将数据库移出服务器以避免单点故障。同时,设置数据复制和分片以满足可用性和可扩展性要求。
- 文件存储:使用Amazon S3进行文件存储。为确保可用性和耐用性,文件在两个独立的地理区域中进行复制。
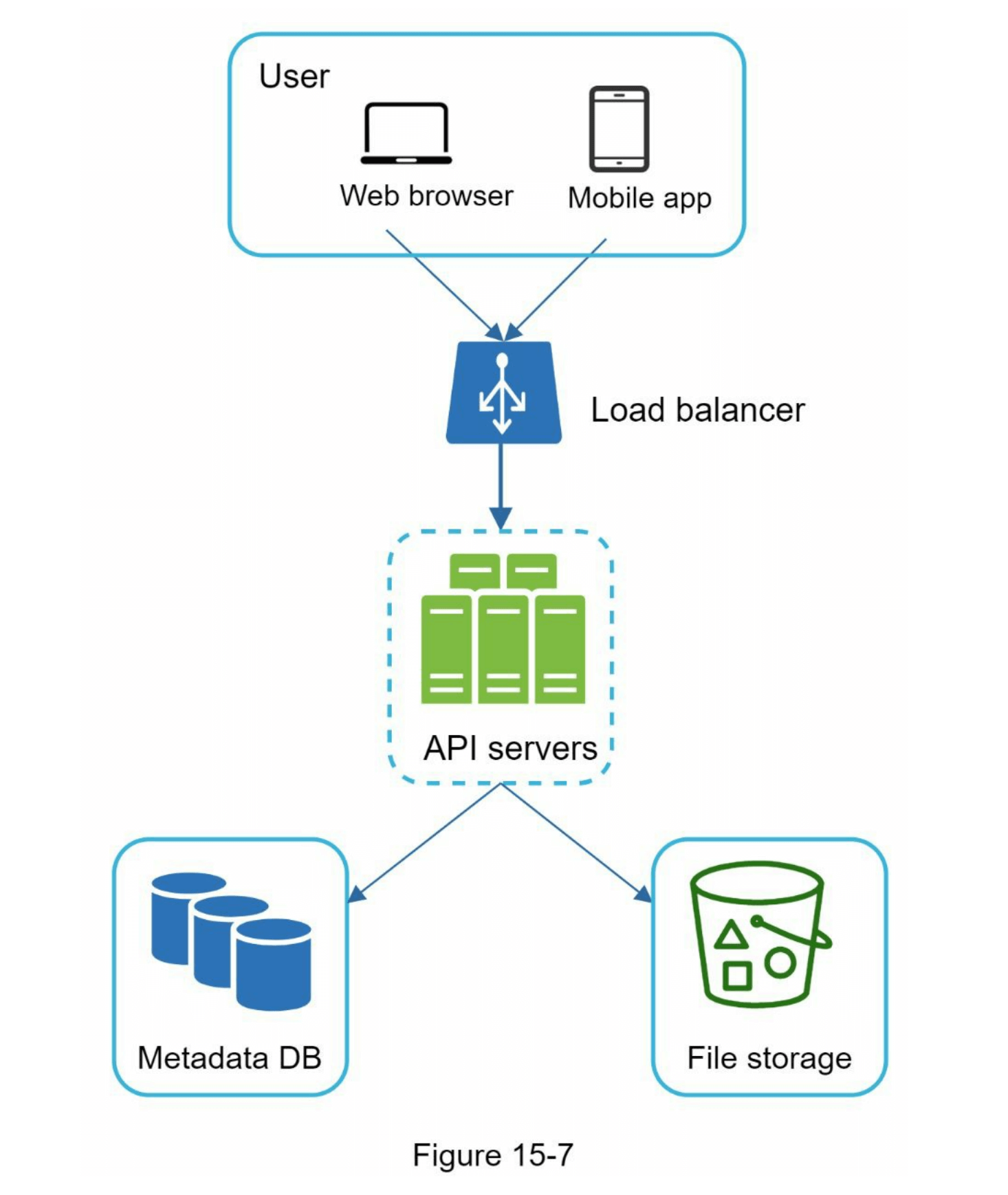
在应用上述改进后,你成功地将Web服务器、元数据数据库和文件存储与单个服务器解耦。更新后的设计如图15-7所示。
同步冲突 (Sync conflicts)
对于像Google Drive这样的大型存储系统,偶尔会发生同步冲突。当两个用户同时修改同一个文件或文件夹时,就会发生冲突。我们如何解决这个冲突?我们的策略是:第一个被处理的版本获胜,后处理的版本将收到冲突。图15-8展示了一个同步冲突的示例。
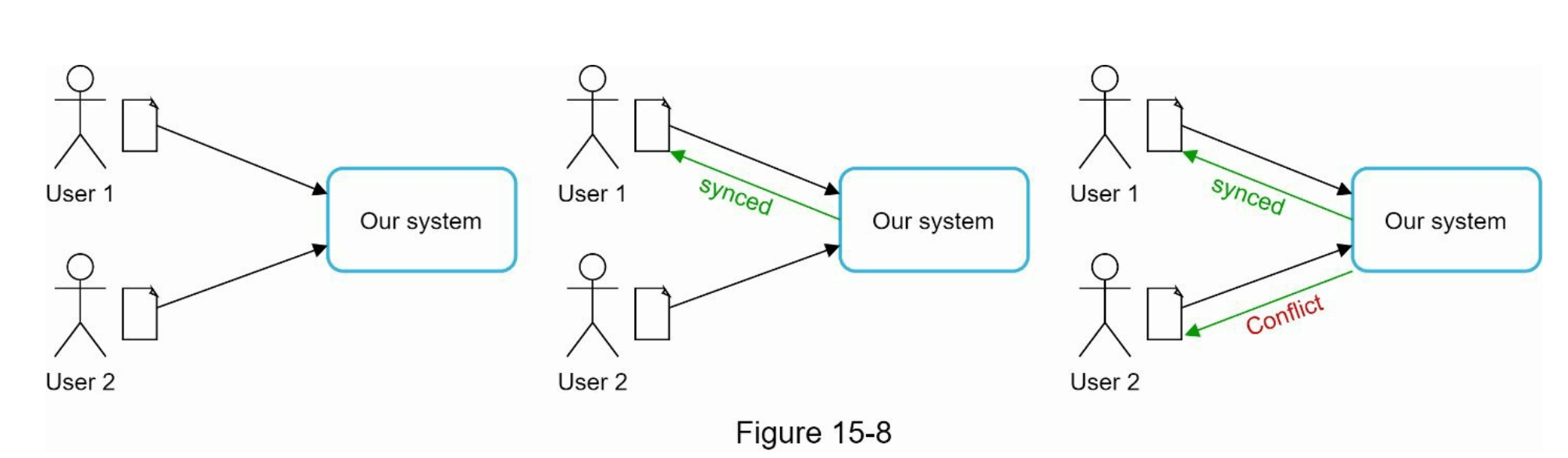
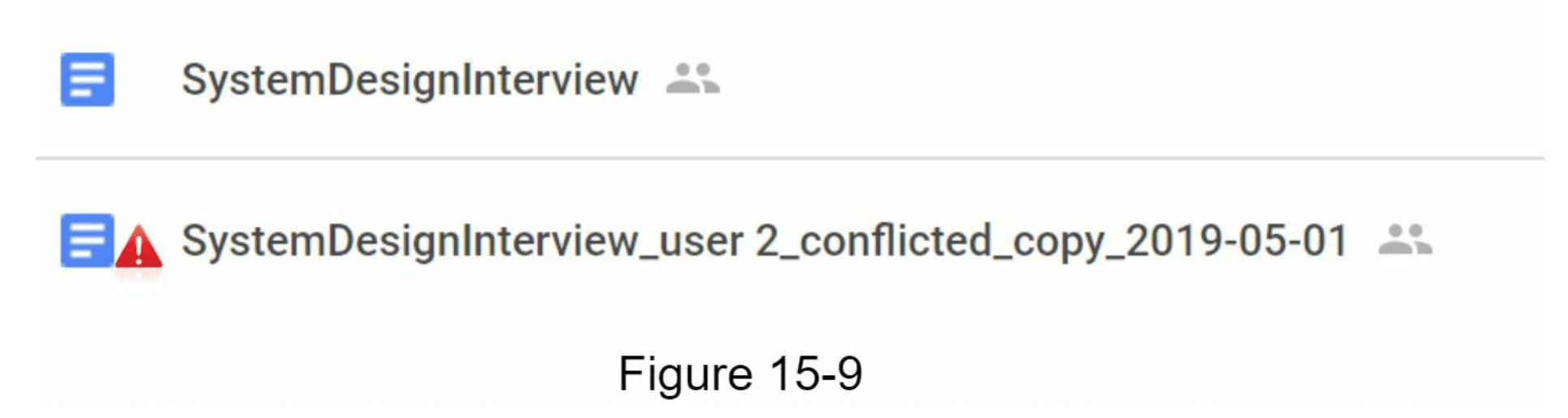
在图15-8中,用户1和用户2尝试同时更新同一个文件,但用户1的文件首先被我们的系统处理。用户1的更新操作通过了,但用户2遇到了同步冲突。那么我们如何为用户2解决这个冲突呢?我们的系统会同时呈现两个相同文件的副本:用户2的本地副本和来自服务器的最新版本(见图15-9)。用户2可以选择合并两个文件或用一个版本覆盖另一个版本。
当多个用户同时编辑同一个文档时,保持文档同步是具有挑战性的。感兴趣的读者可以参考相关材料 [4] [5]。
高层设计
图15-10展示了提议的高层设计。让我们逐个检查系统的各个组件。
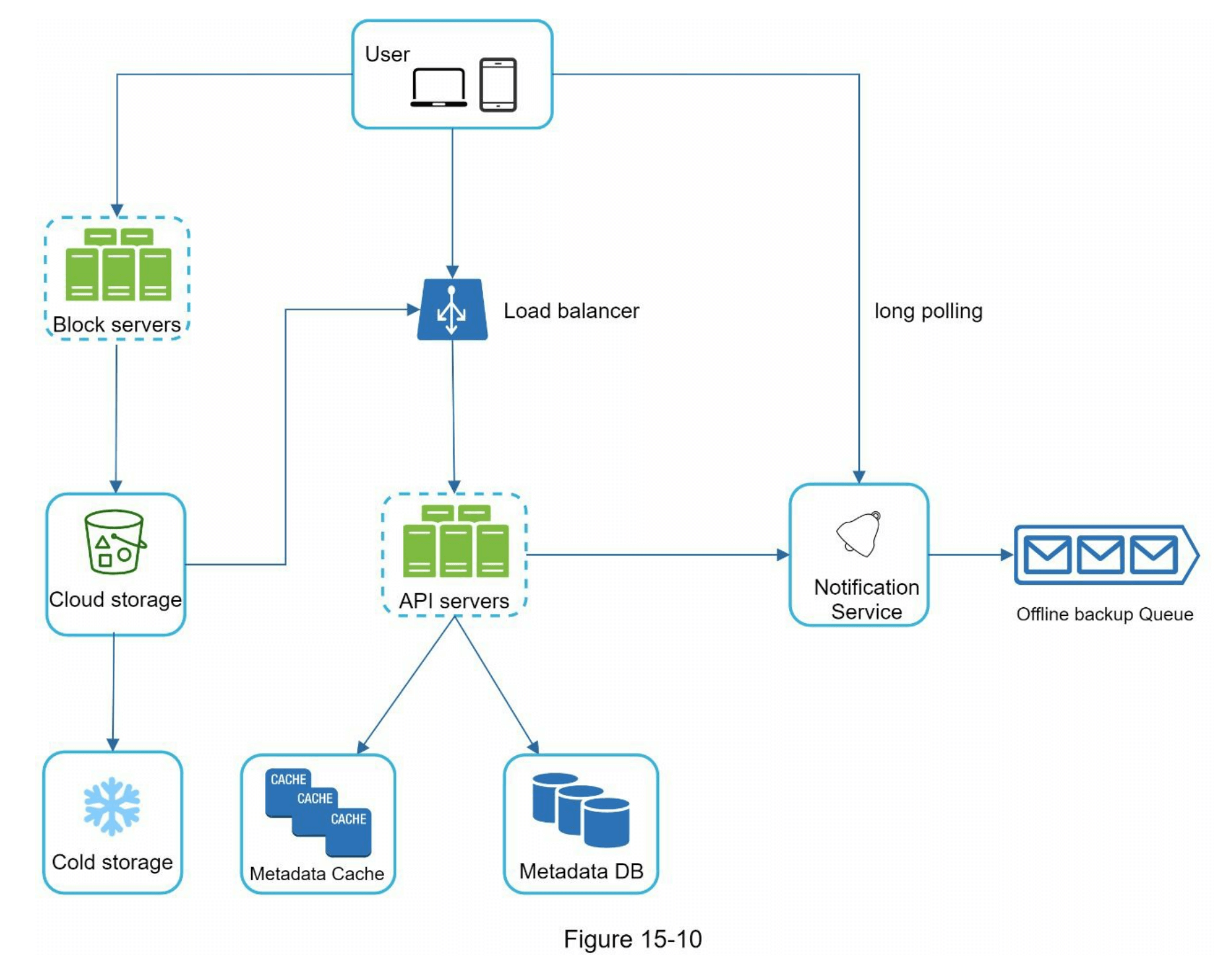
用户:用户可以通过浏览器或移动应用程序使用该应用。
块服务器:块服务器将数据块上传到云存储。块存储(也称为块级存储)是一种在云环境中存储数据文件的技术。一个文件可以分成多个数据块,每个块都有一个唯一的哈希值,存储在我们的元数据数据库中。每个数据块被视为一个独立的对象,并存储在我们的存储系统(S3)中。为了重构一个文件,这些数据块会按特定顺序组合。至于块的大小,我们以Dropbox为参考:它将块的最大大小设定为4MB [6]。
云存储:文件被拆分成更小的数据块并存储在云存储中。
冷存储:冷存储是一种用于存储不活跃数据的计算机系统,这意味着文件在很长时间内未被访问。
负载均衡器:负载均衡器在API服务器之间均匀分配请求。
API服务器:这些服务器几乎负责除了上传流程以外的所有操作。API服务器用于用户身份验证、管理用户资料、更新文件元数据等。
元数据数据库:它存储用户、文件、数据块、版本等的元数据。请注意,文件存储在云中,而元数据数据库仅包含元数据。
元数据缓存:部分元数据被缓存以实现快速检索。
通知服务:这是一个发布/订阅系统,允许数据在特定事件发生时从通知服务传输到客户端。在我们的具体案例中,通知服务会在文件被添加、编辑或移除时通知相关客户端,以便它们可以拉取最新的更改。
离线备份队列:如果客户端处于离线状态,无法拉取最新的文件更改,离线备份队列将存储信息,以便在客户端上线时同步这些更改。
我们已经从高层次讨论了Google Drive的设计。一些组件比较复杂,值得仔细检查;我们将在深入讨论中详细讨论这些内容。
第3步 - 设计深入分析
在本节中,我们将详细探讨以下几个方面:块服务器、元数据数据库、上传流程、下载流程、通知服务、节省存储空间及故障处理。
块服务器
对于经常更新的大文件,每次更新时发送整个文件会消耗大量的带宽。为了最小化传输的数据量,提出了两种优化方案:
- 增量同步:当文件被修改时,使用同步算法 [7] 8,只同步修改过的块,而不是整个文件。
- 压缩:对块进行压缩可以显著减少数据量。根据文件类型,使用不同的压缩算法对块进行压缩。例如,gzip 和 bzip2 用于压缩文本文件,而图像和视频则需要使用不同的压缩算法。
在我们的系统中,块服务器负责文件上传的主要工作。块服务器处理从客户端传来的文件,将文件分割成多个块,对每个块进行压缩和加密。与其将整个文件上传至存储系统,不如仅传输修改过的块。
图15-11展示了当新文件添加时,块服务器的工作流程:
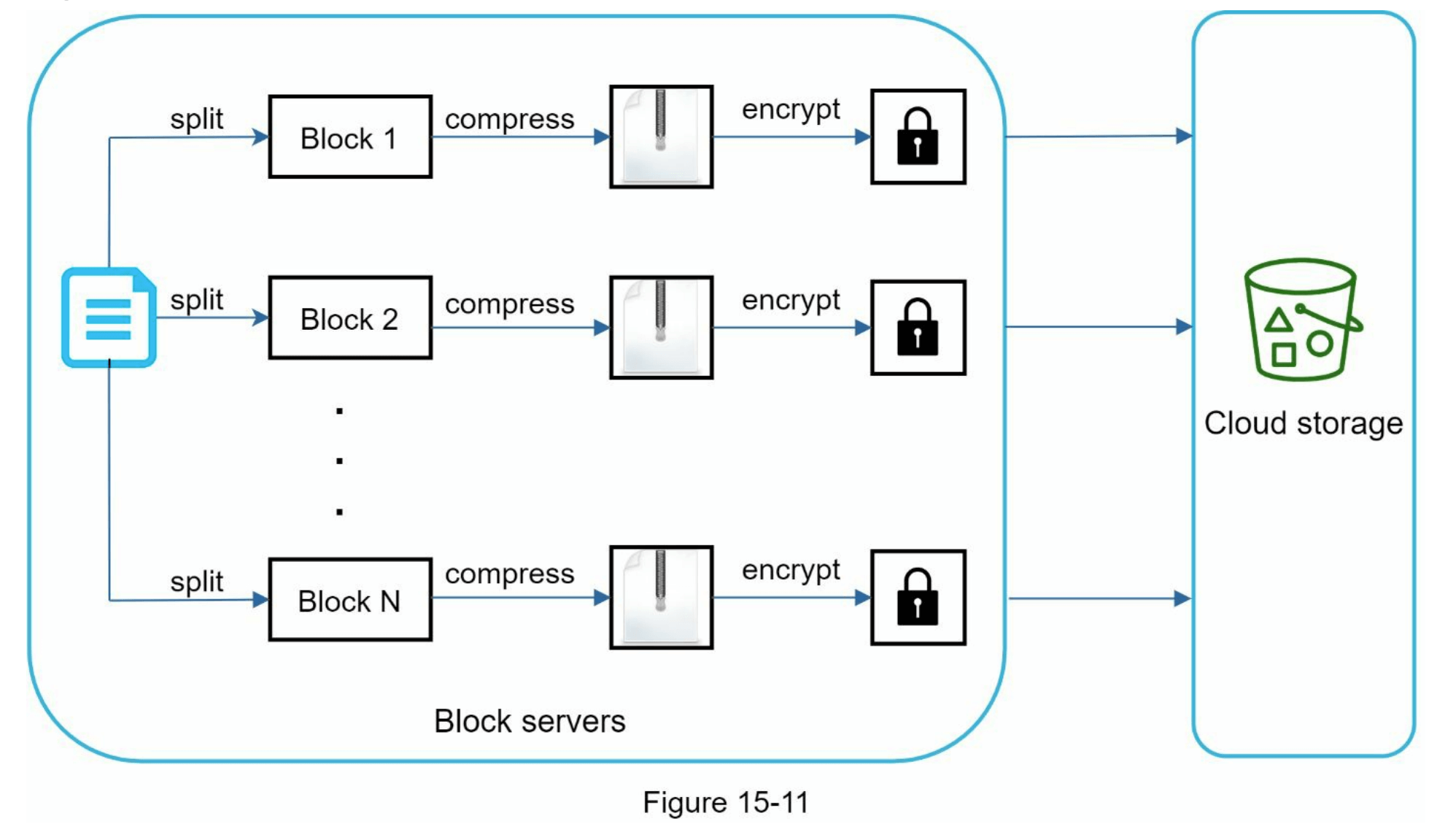
- 文件被分割成更小的块。
- 每个块使用压缩算法进行压缩。
- 为了确保安全性,每个块在发送到云存储之前都会被加密。
- 块上传至云存储。
图15-12展示了增量同步的流程,即只有修改过的块会传输到云存储。高亮显示的“块2”和“块5”表示已修改的块。通过增量同步,只有这两个块会被上传到云存储。
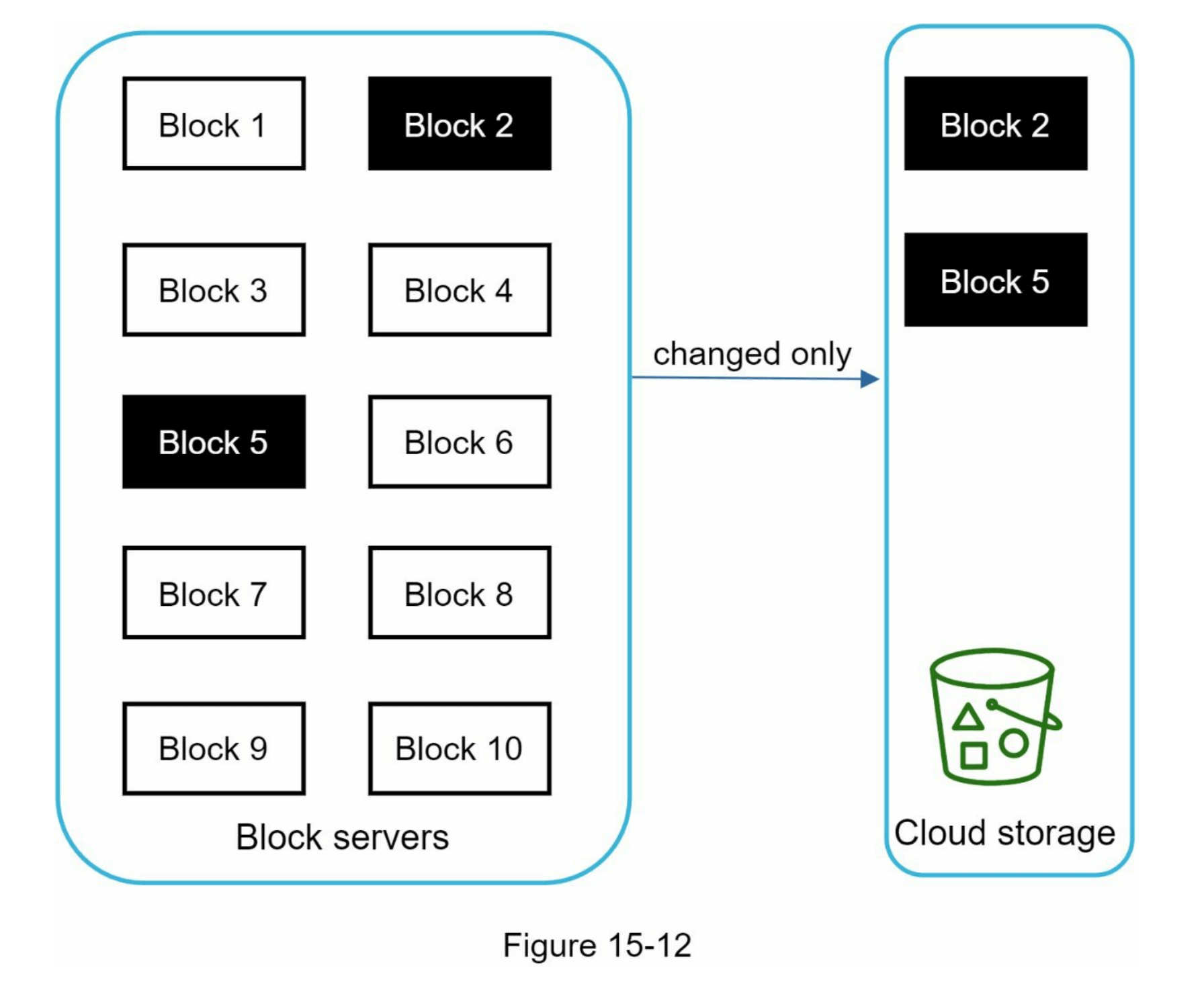
块服务器通过提供增量同步和压缩功能帮助我们节省网络流量。
高一致性需求
我们的系统默认需要强一致性。文件在同一时间被不同客户端显示不一致是不可接受的。因此,系统必须为元数据缓存和数据库层提供强一致性。
内存缓存默认采用最终一致性模型,这意味着不同的副本可能拥有不同的数据。为了实现强一致性,我们必须确保以下几点:
- 缓存副本中的数据与主数据保持一致。
- 在数据库写入时使缓存失效,以确保缓存和数据库中的数据保持相同的值。
在关系型数据库中实现强一致性比较容易,因为它维护ACID(原子性、一致性、隔离性、持久性)属性 [9]。然而,NoSQL数据库默认不支持ACID属性,因此ACID属性必须通过同步逻辑以编程方式实现。在我们的设计中,我们选择关系型数据库,因为它原生支持ACID属性。
元数据数据库
图15-13展示了数据库的模式设计。请注意,这是一个高度简化的版本,只包含最重要的表和关键字段。
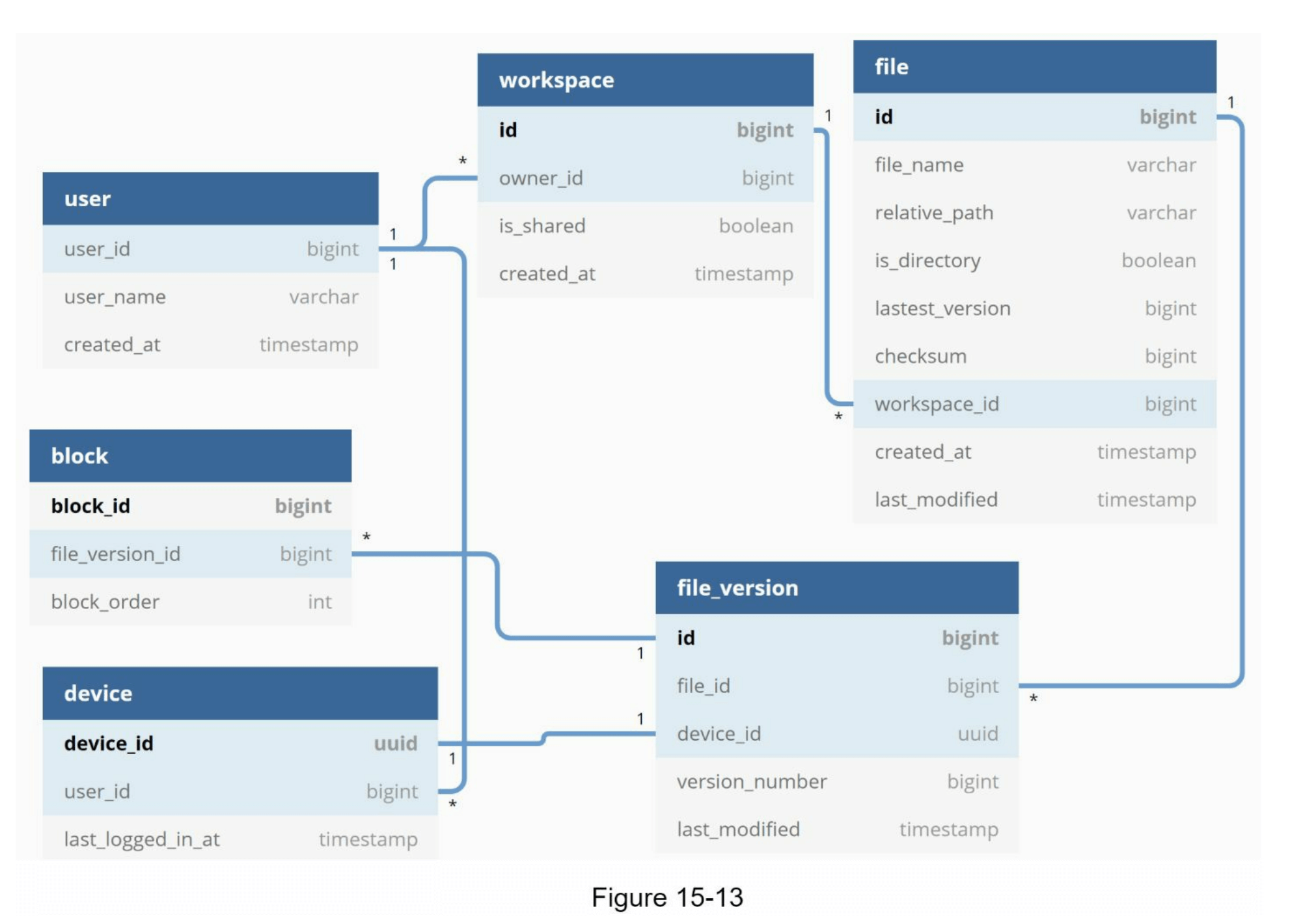
User:用户表包含用户的基本信息,例如用户名、电子邮箱、个人头像等。
Device:设备表存储设备信息。Push_id用于发送和接收移动推送通知。请注意,一个用户可以拥有多个设备。
Namespace:命名空间是用户的根目录。
File:文件表存储与最新文件相关的所有内容。
File_version:该表存储文件的版本历史。为了保持文件修订历史的完整性,已有的行是只读的。
Block:该表存储与文件块相关的所有信息。任何版本的文件都可以通过将所有块按正确顺序组合重建。
上传流程
接下来,我们讨论客户端上传文件时的过程。为了更好地理解这个流程,我们绘制了图15-14中的序列图。
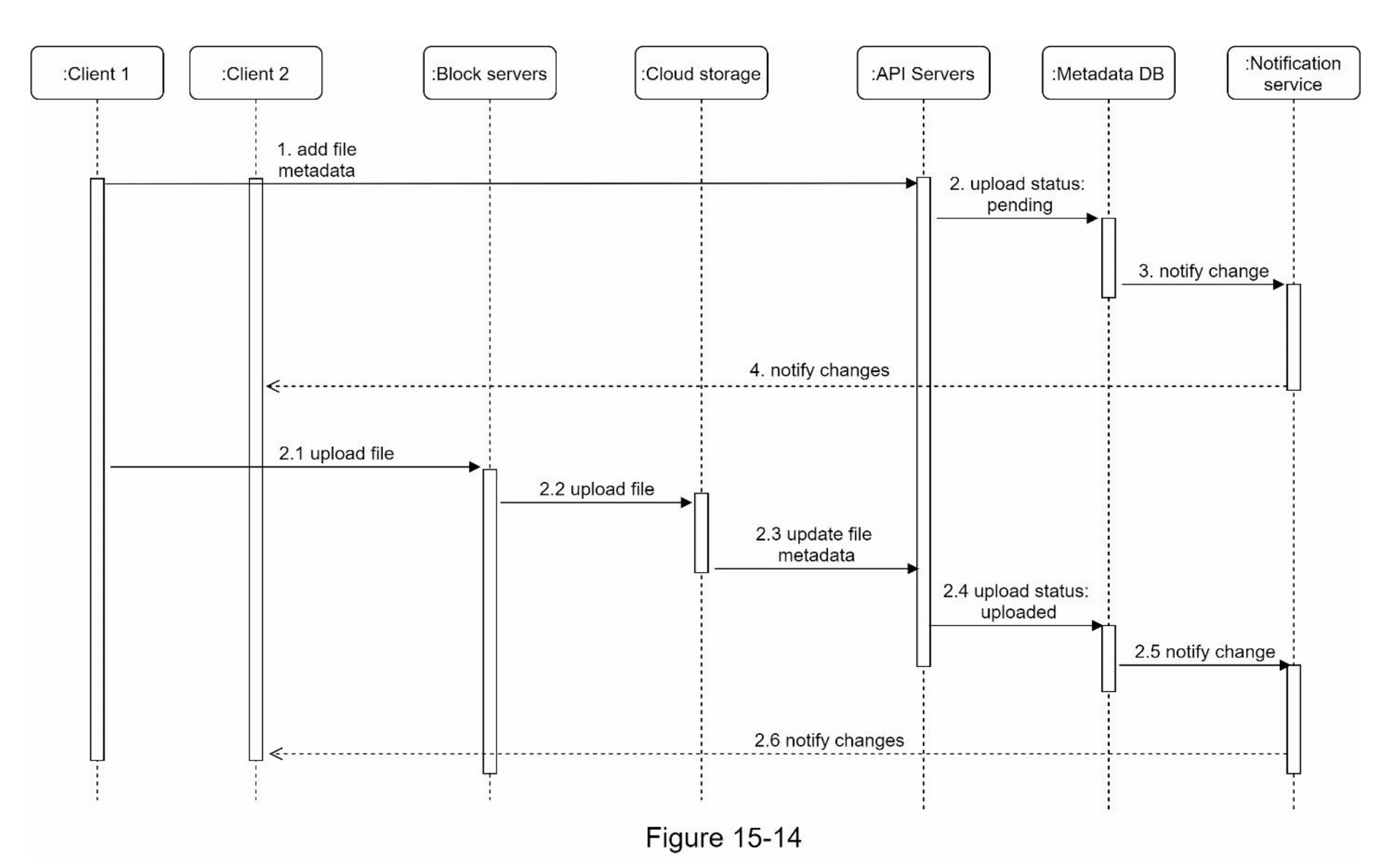
在图15-14中,有两条并行发送的请求:添加文件元数据和将文件上传到云存储。两条请求均来自客户端1。
添加文件元数据
- 客户端1发送请求,添加新文件的元数据。
- 将新文件的元数据存储到元数据数据库中,并将文件上传状态更改为“待处理”。
- 通知服务通知相关客户端有新文件正在添加。
- 通知服务告知相关客户端(如客户端2)文件正在上传。
上传文件到云存储
2.1 客户端1将文件内容上传到块服务器。
2.2 块服务器将文件切割成块,压缩、加密每个块,然后上传到云存储。
2.3 一旦文件上传完成,云存储触发上传完成的回调请求,发送至API服务器。
2.4 文件状态在元数据数据库中更改为“已上传”。
2.5 通知服务被告知文件状态已更改为“已上传”。
2.6 通知服务告知相关客户端(如客户端2)文件已全部上传完成。
当文件被编辑时,流程相似,因此不再赘述。
下载流程
下载流程在文件被其他地方添加或编辑时触发。客户端如何知道文件被其他客户端添加或编辑?有两种方式:
- 如果客户端A在线,其他客户端更改文件时,通知服务会告知客户端A有更改发生,客户端需要拉取最新数据。
- 如果客户端A离线,其他客户端更改文件时,数据将保存到缓存中。当离线客户端重新上线时,它将拉取最新的更改。
一旦客户端知道文件已更改,它首先通过API服务器请求元数据,然后下载相应的块以构建文件。图15-15展示了详细的流程。请注意,由于空间限制,图中仅展示了最重要的组件。
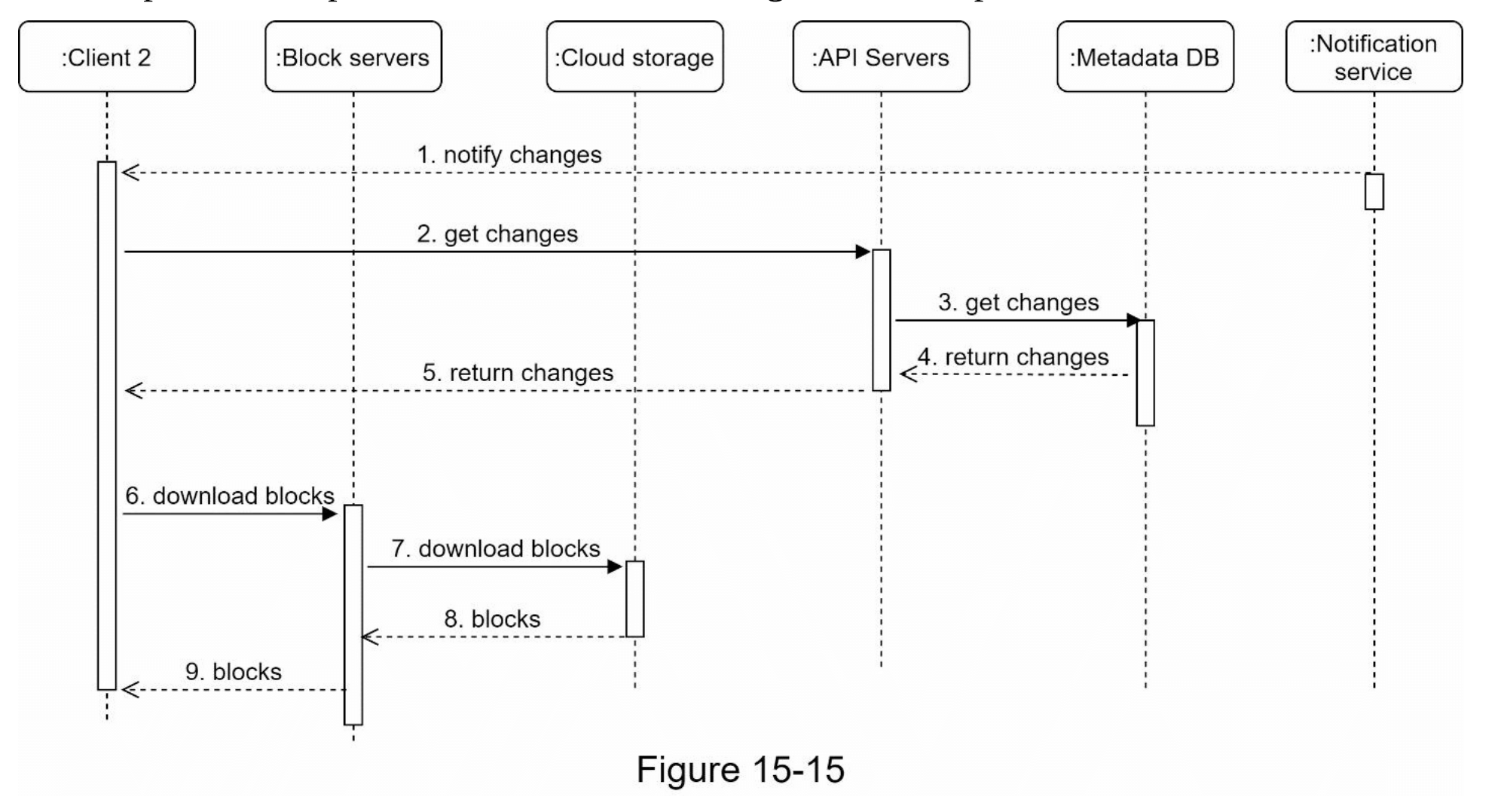
- 通知服务告知客户端2文件在其他地方发生了更改。
- 客户端2知道有新更新后,发送请求获取元数据。
- API服务器调用元数据数据库,获取更改的元数据。
- 元数据返回给API服务器。
- 客户端2获取元数据。
- 客户端收到元数据后,发送请求给块服务器下载文件块。
- 块服务器首先从云存储下载相应的块。
- 云存储将块返回给块服务器。
- 客户端2下载所有新的块来重建文件。
通知服务
为了维护文件的一致性,任何在本地执行的文件更改都需要通知其他客户端,以减少冲突。通知服务就是为此目的而构建的。从高级别来看,通知服务允许数据在事件发生时传输到客户端。以下是几种可选方案:
- 长轮询:Dropbox使用长轮询 [10]。
- WebSocket:WebSocket提供客户端和服务器之间的持久连接,支持双向通信。
虽然两种方式都很好用,但我们选择了长轮询,原因如下:
- 通知服务的通信不是双向的。服务器将文件更改的信息发送给客户端,而不是反之。
- WebSocket适合实时双向通信,例如聊天应用。对于Google Drive来说,通知是间歇性的,数据量并不大。
在长轮询模式下,每个客户端都会与通知服务建立一个长轮询连接。如果检测到文件更改,客户端会关闭长轮询连接。关闭连接意味着客户端必须连接到元数据服务器下载最新的更改。收到响应或连接超时后,客户端会立即发送新请求以保持连接。
节省存储空间
为了支持文件版本历史并确保可靠性,同一个文件的多个版本存储在多个数据中心中。频繁备份所有文件修订版本会迅速占满存储空间。为了降低存储成本,提出了三种技术:
- 去重数据块:在账户级别消除冗余块是节省空间的简单方法。如果两个块具有相同的哈希值,则它们是相同的。
- 采用智能数据备份策略。可以应用两种优化策略:
- 设置限制:我们可以为存储的版本数量设置上限。如果达到上限,最旧的版本将被新版本替换。
- 仅保留有价值的版本:有些文件可能会被频繁编辑。例如,对某个频繁修改的文档,每次保存可能会在短时间内保存上千次。为了避免不必要的副本,我们可以限制保存的版本数量,并对最近的版本赋予更多权重。通过实验可以找到最佳的保存版本数量。
- 将不常用的数据移到冷存储中。冷数据是指几个月或几年内未被访问的数据。像Amazon S3 Glacier [11]这样的冷存储比S3更便宜。
故障处理
在大规模系统中,故障可能随时发生,因此我们必须采用设计策略来应对这些故障。面试官可能会对你如何处理以下系统故障感兴趣:
- 负载均衡器故障:如果负载均衡器出现故障,备用均衡器将会接管流量。负载均衡器通常使用心跳机制相互监控,心跳是一种在负载均衡器之间定期发送的信号。如果某个负载均衡器在一段时间内没有发送心跳,则视为失效。
- 块服务器故障:如果块服务器故障,其他服务器将接管未完成或待处理的任务。
- 云存储故障:S3桶在不同区域进行了多次复制。如果某一区域的文件不可用,可以从其他区域获取文件。
- API服务器故障:API服务器是无状态服务。如果某个API服务器失效,流量将通过负载均衡器重定向到其他API服务器。
- 元数据缓存故障:元数据缓存服务器被多次复制。如果某个节点宕机,仍然可以访问其他节点获取数据。我们将启动一个新缓存服务器替换故障服务器。
- 元数据数据库故障:
- 主数据库宕机:如果主数据库宕机,将提升其中一个从数据库为新的主数据库,并启动一个新的从数据库节点。
- 从数据库宕机:如果从数据库宕机,可以使用另一个从数据库进行读操作,并启动另一个数据库服务器替换故障节点。
- 通知服务故障:每个在线用户都会与通知服务器保持长轮询连接。因此,每个通知服务器都连接着许多用户。据2012年Dropbox演讲 [6] 显示,每台服务器可以维持超过100万个连接。如果某台服务器宕机,所有的长轮询连接将丢失,客户端必须重新连接到另一台服务器。尽管一台服务器可以维持大量的开放连接,但它无法一次性重新连接所有丢失的连接。与所有丢失的客户端重新连接是一个相对较慢的过程。
- 离线备份队列故障:队列被多次复制。如果某个队列失效,队列的消费者可能需要重新订阅备份队列。
第 4 步 - 总结
在本章中,我们提出了一个支持 Google Drive 的系统设计。通过强一致性、低网络带宽以及快速同步的结合,使得该设计非常有趣。我们的设计包含两个流程:文件元数据管理和文件同步。通知服务是系统中的另一个重要组件,它使用长轮询保持客户端与文件更改的同步。
与任何系统设计面试题一样,没有完美的解决方案。每个公司都有其独特的约束条件,因此你必须根据这些约束设计系统。了解设计的权衡和技术选择非常重要。如果还剩几分钟时间,可以讨论不同的设计选择。
例如,我们可以直接从客户端将文件上传到云存储,而不是通过块服务器。该方法的优点是文件上传速度更快,因为文件只需要传输一次到云存储。在我们的设计中,文件先传输到块服务器,然后再传输到云存储。然而,这种新方法有一些缺点:
- 首先,同样的分块、压缩和加密逻辑必须在不同的平台(如iOS、Android、Web)上实现。这容易出错并且需要大量的工程工作量。而在我们的设计中,这些逻辑都集中在块服务器上实现。
- 其次,由于客户端容易被黑客攻击或篡改,在客户端上实现加密逻辑并不理想。
另一个有趣的系统演进是将在线/离线逻辑移到一个独立的服务中,我们称之为“状态服务”。通过将状态服务从通知服务器中分离出来,其他服务可以更容易地集成在线/离线功能。
恭喜你走到了这一步!为自己鼓掌吧,干得好!
参考文献
[1] Google Drive: https://www.google.com/drive/
[2] Upload file data: https://developers.google.com/drive/api/v2/manage-uploads
[3] Amazon S3: https://aws.amazon.com/s3
[4] Differential Synchronization https://neil.fraser.name/writing/sync/
[5] Differential Synchronization youtube talk https://www.youtube.com/watch?v=S2Hp_1jqpY8
[6] How We’ve Scaled Dropbox: https://youtu.be/PE4gwstWhmc
[7] Tridgell, A., & Mackerras, P. (1996). The rsync algorithm. https://www.andrew.cmu.edu/course/15-749/READINGS/required/cas/tridgell96.pdf
[8] Librsync. (n.d.). Retrieved April 18, 2015, from https://github.com/librsync/librsync
[9] ACID: https://en.wikipedia.org/wiki/ACID
[10] Dropbox security white paper: https://www.dropbox.com/static/business/resources/Security_Whitepaper.pdf
[11] Amazon S3 Glacier: https://aws.amazon.com/glacier/faqs/